(Java - 24) 컬렉션 프레임워크(Collection)
자바의 컬렉션 프레임워크에 대해서
포스트에서 설명하는 컬렉션들은 자료구조에서 상세히 설명한다.
1) 컬렉션 프레임워크(Collection)
-
Collection(다수의 객체)을 다루기 위한 프레임워크 - 데이터를 다루기 위한 자료구조를 표현하고 사용할 수 있는 클래스들 제공
-
Collection,List,Set,Map등 과 같은 코어 인터페이스 제공 - 코어 인터페이스를 구현한
ArrayList,LinkedList,HashSet,HashMap, 등 과 같은 클래스들 제공
정리하자면.
- 모든 컬렉션 타입들이
Collection을 구현함으로써, 개발자들은 다양한 컬렉션에 대해 일관된 방식으로 사용할 수 있다 - 새로운 컬렉션을 만들 때, 기존의
Collection프레임워크를 사용해서, 기존에 정의된 알고리즘과 메서드들을 사용할 수 있게 된다 -
Collection을 구현함으로써, 다양한 컬렉션 타입들을 같은 타입으로 다룰 수 있게 해서, 다형성을 활용할 수 있도록한다.
2) 컬렉션의 구조
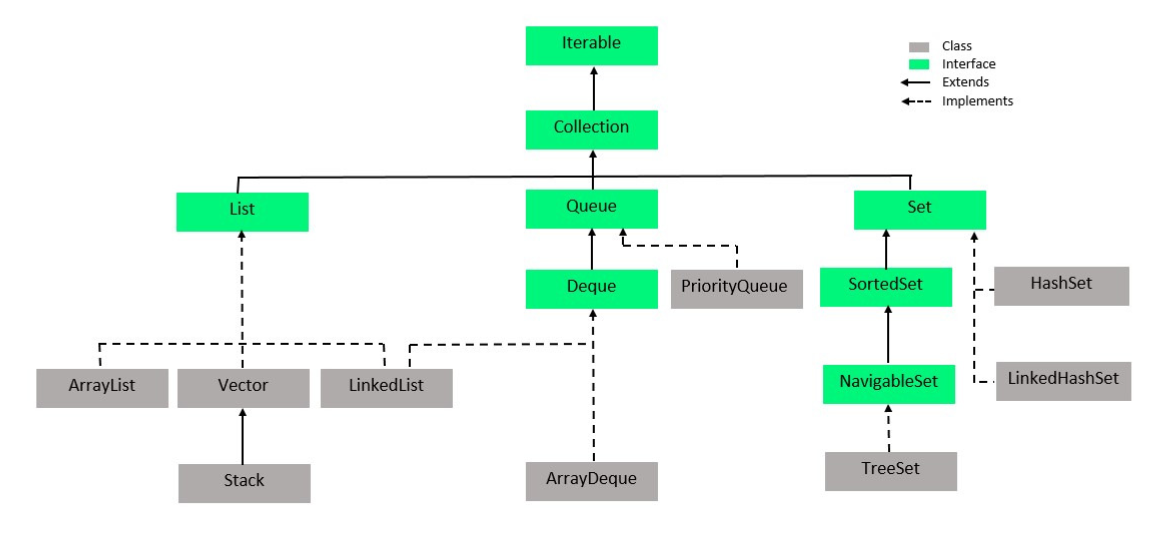
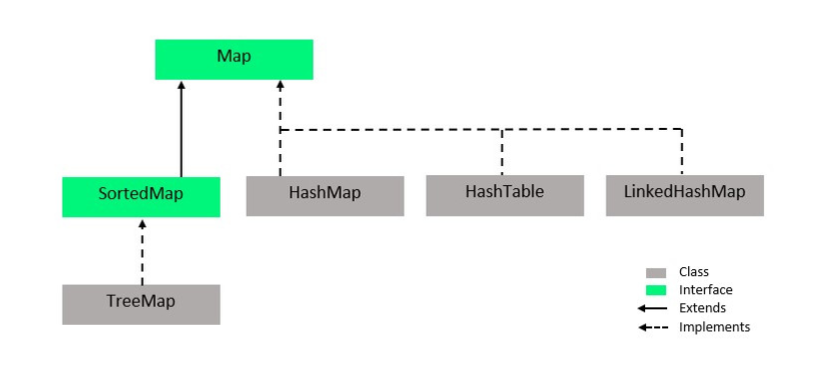
geeksforgeeks - java collection inheritence
3) Iterable, Iterator
3.1 Iterable, Iterator 설명
자료 구조를 순회하기 위해서는 순회 방법에 대한 로직이 필요하다. 가령 배열을 인덱스 하나씩 증가시키면서 요소를 순회한다면, 연결 리스트는 node.next를 이용해서 null이 나올때 까지 순회한다. 이 처럼 각 자료 구조마다 순회하는 방법이 다르기 때문에, 자료 구조의 구현 방법과 관계 없이 모든 자료 구조를 동일한 방법으로 순회할 수 있는 추상화된 인터페이스가 있다면 개발자 입장에서는 편리할 것이다.
이런 문제를 해결하기 위해 자바는 Iterable, Iterator 인터페이스를 제공한다. Iterable 인터페이스에 대해 먼저 알아보자.
1
2
3
public interface Iterable<T> {
Iterator<T> iterator();
}
-
Iterable을 구현하는 클래스는Iterator를 반환하는 메서드iterator()를 오버라이딩해야 함 - 그러면 우리가 사용할 반복자(
Iterator)를 또 만들어야한다 -
Iterator에 순회 방법에 대한 로직을 구현한다고 생각하면 편하다
1
2
3
4
public interface Iterator<E> {
boolean hasNext();
E next();
}
-
hasNext(): 다음 요소가 있는지 확인. 없으면false반환. -
next(): 다음 요소 반환. 내부에 있는 위치(커서)를 다음으로 이동.
정리하자면, 자료 구조를 순회하기 위해서는 자료 구조에 Iterator(반복자)를 제공하면 된다. 반복자에는 어떤 방식으로 순회할 것인지 구현하면 된다. 여기서 중요한 것은 Iterator를 단독으로 사용할 수 없다는 것이다. 먼저 순회의 대상이 되는 자료 구조가 Iterable 인터페이스를 구현해야하고, iterator() 메서드를 통해 구현한 반복자(Iterator)를 반환하도록 하면 된다.
3.2 Iterator 구현
- 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화한 인터페이스
- 컬렉션에
iterator()를 호출해서Iterator를 구현한 객체를 얻어서 사용한다 - Java docs -
Iterator
Iterator를 구현하는 과정을 살펴보자.
MyIterator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class MyIterator implements Iterator<Integer> {
private int currentIndex = -1;
private int[] targetArr;
public MyIterator(int[] targetArr) {
this.targetArr = targetArr;
}
@Override
public boolean hasNext() {
return currentIndex < targetArr.length - 1;
}
@Override
public Integer next() {
return targetArr[++currentIndex];
}
}
- 생성자를 통해
MyIterator가 사용할 배열 참조. 이 배열을 순회할 것이다. -
currentIndex: 현재의 인덱스 -
hasNext(): 다음 요소가 있는지 검사.null이 나오면false반환 -
next()-
currentIndex를 하나 증가 시키고, 다음 요소를 반환한다 - 인덱스는
0부터 시작하기 때문에currentIndex는 가장 초기에는-1을 가진다
-
Iterator를 사용하기 위해서는 Iterator를 사용할 자료 구조가 Iterable 인터페이스를 구현해야한다.
MyArray
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class MyArray implements Iterable<Integer> {
private int[] numbers;
public MyArray(int[] numbers) {
this.numbers = numbers;
}
@Override
public Iterator<Integer> iterator() {
return new MyArrayIterator(numbers);
}
}
- 직접 구현한
MyArray자료 구조는Iterable인터페이스를 구현한다 - 오버라이딩한
iterator()메서드는 앞에서 만든Iterator인MyIterator를 반환하면 된다
IteratorMain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class IteratorMain {
public static void main(String[] args) {
MyArray myArray = new MyArray(new int[]{1, 2, 3, 4});
Iterator<Integer> iterator = myArray.iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println("value = " + value);
}
System.out.println("--------");
// 다시 Iterator 객체를 사용하기 위해서는 새로 선언해야 한다
iterator = myArray.iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println("value = " + value);
}
}
}
1
2
3
4
5
6
7
8
9
value = 1
value = 2
value = 3
value = 4
--------
value = 1
value = 2
value = 3
value = 4
-
Iterator객체를 다시 사용하기 위해서는 새로운Iterator객체를 선언해야 함
우리가 사용하는 컬렉션 프레임워크의 자료 구조들은 이미 Iterable, Iterator가 전부 구현이 되어있기 때문에 순회기능을 바로 사용할 수 있다.
참고로
Map에 반복자를 사용하기 위해서는keySet(),values()등을 통해서 호출한 후에 사용해야 한다.
Map은Iterable인터페이스를 구현하지 않는다.
4) List
- 순서가 있고, 중복을 허용한다
- Java docs -
List
4.1 ArrayList
- 저장공간으로 배열 사용(배열 기반)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
public class ArrayListMain {
public static void main(String[] args) {
// 1. ArrayList 생성
// List를 사용하는 것이 다형성 측면에서 더 유리
ArrayList<String> fruits = new ArrayList<>(); // String 타입만 넣을 수 있는 ArrayList
// 2. ArrayList에 요소를 추가 (add)
// add(요소)를 사용하면 끝에 추가해줌
fruits.add("Banana");
fruits.add("Apple");
fruits.add("Grape");
fruits.add("Mango");
// add(인덱스, 요소) 해당 인덱스 위치에 삽입해줌
fruits.add(2, "Blueberry"); // 2번 인덱스에 "BlueBerry" 삽입
// 3. 요소에 접근
// for-each문 사용
System.out.println("---------Print the ArrayList(for-each)---------");
for (String fruit : fruits) {
System.out.println(fruit);
}
// get() 사용
System.out.println("-----------Print the ArrayList(get())----------");
for (int i=0; i< fruits.size(); i++) {
System.out.println(fruits.get(i)); // i번째 인덱스의 요소 반환
}
// 4. ArrayList의 길이 (size)
System.out.println("-----------------------------------------------");
System.out.println("fruits의 길이 : "+fruits.size());
// 5. ArrayList의 요소 제거 (remove)
System.out.println("-----------------------------------------------");
String removeFruit = "Apple";
fruits.remove(removeFruit);
System.out.println(removeFruit+" has been removed from the ArrayList");
System.out.println("---------------Updated ArrayList---------------");
for (String fruit : fruits) {
System.out.println(fruit);
}
System.out.println("fruits의 길이 : "+fruits.size());
// 6. 특정 요소의 포함 여부 (contain)
System.out.println("-----------------------------------------------");
String searchFruit = "Grape";
if (fruits.contains(searchFruit)) {
System.out.println("The ArrayList contains "+searchFruit);
} else {
System.out.println("The ArrayList does not contain "+searchFruit);
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
---------Print the ArrayList(for-each)---------
Banana
Apple
Blueberry
Grape
Mango
-----------Print the ArrayList(get())----------
Banana
Apple
Blueberry
Grape
Mango
-----------------------------------------------
fruits의 길이 : 5
-----------------------------------------------
Apple has been removed from the ArrayList
---------------Updated ArrayList---------------
Banana
Blueberry
Grape
Mango
fruits의 길이 : 4
-----------------------------------------------
The ArrayList contains Grape
-
remove를 이용해 요소를 제거하는 과정- 삭제할 데이터의 아래 데이터를 전부 한 칸씩 위로 복사 후 덮어씀 → 마지막 데이터는
null로 변경 →size값을 하나 감소 - 복사하는 과정이 부담되기 때문에
remove를 사용하는 경우 끝 인덱스 부터 시작하는 것을 권장- 마지막 부터
remove하는 경우 배열 복사가 없음
- 마지막 부터
- 삭제할 데이터의 아래 데이터를 전부 한 칸씩 위로 복사 후 덮어씀 → 마지막 데이터는
4.2 LinkedList
- 배열의 단점
- 크기 변경 불가. 더 큰 배열을 사용하기 위해서는 큰 배열 생성 → 복사 → 참조 변경의 과정을 거쳐야 함
- 앞의 데이터(비순차적인 데이터)를 추가하거나 삭제하는 것이 비효율적
- 배열의 단점 보완을 위한
LinkedList - 불연속으로 존재하는 데이터를 연결
Java의 컬렉션 프레임워크의
LinkedList는 양방향 연결 리스트(doubly linked list)로 구현되어 있다- 접근의 경우
ArrayList가 더 빠름
1
2
3
4
5
class Node<E> {
Node<E> next; // 다음 노드 주소
Node<E> prev; // 이전 노드 주소
E item; // 데이터 저장
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class LinkedListMain {
public static void main(String[] args) {
// 1. LinkedList 생성
LinkedList<String> linkedList = new LinkedList<>(); // String 타입만 넣을 수 있는 ArrayList
// 2. LinkedList에 요소를 추가 (add)
// add(요소)를 사용하면 끝에 추가해줌
linkedList.add("Banana");
linkedList.add("Apple");
linkedList.add("Apple");
// 특정 인덱스 위치에 추가
linkedList.add(2, "Blueberry");
linkedList.addFirst("Orange"); // 앞에 추가
linkedList.addLast("Mango"); // 뒤에 추가
// 3. LinkedList 출력
System.out.println("---------Print the LinkedList---------");
for (String item : linkedList) {
System.out.println(item);
}
}
}
1
2
3
4
5
6
7
---------Print the LinkedList---------
Orange
Banana
Apple
Blueberry
Apple
Mango
-
ArrayList와 마찬가지로List인터페이스를 구현하기 때문에ArrayList처럼 사용하면 됨
5) Set
- 순서가 없고, 중복을 허용하지 않는다
- 순서를 유지하고 싶으면
LinkedHashSet사용 가능
- 순서를 유지하고 싶으면
- Java docs -
Set
5.1 HashSet
저장에 해시 알고리즘(hash algorithm) 사용
- 정렬 불가
- 정렬을 위해서는 모든 요소를 리스트에 저장하고 리스트를 정렬
-
hashCode()-
hashCode()를 구현하는 방법은 다양하다
-
-
equals()와hashCode()를 오버라이드 해야 정상 동작- 동일한 객체는 동일한 메모리 주소를 가진다 → 동일한 객체는 동일한 해시코드를 가져야 한다
- 두 객체가
equals()로 동일하다는 뜻은, 두 객체의hashCode()도 동일해야 함 - 반면에 동일 해시코드 값을 가졌다고 동일 객체라는 보장은 없다(해시 충돌의 케이스)
-
retainAll(): 교집합 -
addAll(): 합집합
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
class Book {
private String title;
private String author;
private String isbn;
public Book(String title, String author, String isbn) {
this.title = title;
this.author = author;
this.isbn = isbn;
}
// isbn은 고유하다고 가정하고 isbn만 사용
@Override
public boolean equals(Object o) {
if (this == o) return true; // 현재의 인스턴스가 비교하는 인스턴스(o)와 같은지 확인
if (o == null || getClass() != o.getClass()) return false; // 같은 클래스인지 확인
Book book = (Book) o; // isbn은 Object가 아니라 Book에 존재하기 때문에 사용하기 위해서 형변환
return isbn.equals(book.isbn); // 두 Book 객체의 isbn이 같은지 확인
}
@Override
public int hashCode() {
return Objects.hash(isbn);
}
@Override
public String toString() {
return "Title: "+title+", Author: "+author+", ISBN: "+isbn;
}
}
public class HashSetMain1 {
public static void main(String[] args) {
Set<Book> hashSet = new HashSet<>();
// 1. HashSet에 객체(책) 추가
hashSet.add(new Book("Title1", "Author1", "ISBN123"));
hashSet.add(new Book("Title2", "Author2", "ISBN456"));
hashSet.add(new Book("Title3", "Author3", "ISBN789"));
hashSet.add(new Book("Title4", "Author2", "ISBN999"));
// 2. 똑같은 책 추가 시도 - 이미 존재하기 때문에 추가되지 않음
hashSet.add(new Book("Title3", "Author3", "ISBN789"));
// 3. HashSet 원소 출력
for (Book book : hashSet) {
System.out.println(book);
}
}
}
1
2
3
4
Title: Title2, Author: Author2, ISBN: ISBN456
Title: Title1, Author: Author1, ISBN: ISBN123
Title: Title4, Author: Author2, ISBN: ISBN999
Title: Title3, Author: Author3, ISBN: ISBN789
-
equals()와hashCode()의 오버라이딩은 IDE를 통해서 하자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
public class HashSetMain {
public static void main(String[] args) {
// 1. HashSet 생성
// 요소가 String이면 equals, hashCode 오바라이딩하지 않아도 됨
HashSet<String> hashSet = new HashSet<>();
// 2. HashSet에 원소 추가 (중복 비허용)
hashSet.add("Math");
hashSet.add("English");
hashSet.add("Philosophy");
hashSet.add("Chemistry");
hashSet.add("Chemistry");
// 3. Iterator를 사용해서 HashSet의 원소 출력
System.out.println("----------Print HashSet using Iterator----------");
System.out.println("Elements in the HashSet:");
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 4. 특정 원소가 HashSet에 존재하는지 확인
System.out.println("------------------------------------------------");
String searchElement = "Math";
if (hashSet.contains(searchElement)) {
System.out.println(searchElement + " is present in the HashSet.");
} else {
System.out.println(searchElement + " is not present in the HashSet.");
}
// 5. HashSet에서 원소 제거
System.out.println("------------------------------------------------");
String removeElement = "Chemistry";
hashSet.remove(removeElement);
System.out.println(removeElement + " has been removed from the HashSet.");
// 6. Updated HashSet 출력
System.out.println("---------Updated Elements in the HashSet---------");
for (String fruit : hashSet) {
System.out.println(fruit);
}
// 7. HashSet의 크기
System.out.println("------------------------------------------------");
int size = hashSet.size();
System.out.println("Size of the HashSet: " + size);
// 8. HashSet 비우기
hashSet.clear();
System.out.println("HashSet is now empty.");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
----------Print HashSet using Iterator----------
Elements in the HashSet:
English
Chemistry
Math
Philosophy
------------------------------------------------
Math is present in the HashSet.
------------------------------------------------
Chemistry has been removed from the HashSet.
---------Updated Elements in the HashSet---------
English
Math
Philosophy
------------------------------------------------
Size of the HashSet: 3
HashSet is now empty.
5.2 TreeSet
정렬과 탐색에 유리
- Java의
TreeSet은 Red-Black Tree로 구현- Red-Black Tree는 이진탐색 트리(Binary Search Tree, BST)의 일종
HashSet에 비해 데이터 추가, 삭제하는 시간이 더 소요-
TreeSet은 요소들이 정렬이 되어서 들어감- 정렬 기준이 필요
-
Comparable,Comparator사용
-
- 정렬 기준이 필요
1
2
3
4
5
public class TreeNode<E> {
E data; // 저장할 객체
TreeNode<E> left; // 왼쪽 자식 노드 주소
TreeNode<E> right; // 오른쪽 자식 노드 주소
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person otherPerson) {
if (this.age > otherPerson.age) { // 먼저 나이부터 비교
return 1;
} else if (this.age == otherPerson.age) {
return this.name.compareTo(otherPerson.name); // 만약 나이가 같으면 이름 비교
} else {
return -1;
}
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Person person = (Person) obj;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return name + " is "+age+" years old.";
}
}
public class TreeSetMain1 {
public static void main(String[] args) {
Set<Person> personSet = new TreeSet<>();
// 1. 사람 추가
personSet.add(new Person("Alice", 35));
personSet.add(new Person("Bob", 17));
personSet.add(new Person("Charlie", 25));
personSet.add(new Person("David", 22));
personSet.add(new Person("David", 12));
personSet.add(new Person("Jessie", 35));
personSet.add(new Person("Mark", 35));
personSet.add(new Person("Andy", 25));
personSet.add(new Person("Andy", 25)); // 중복된 요소는 추가되지 않음
// 2. 각 요소 출력
for (Person person : personSet) {
System.out.println(person);
}
}
}
1
2
3
4
5
6
7
8
David is 12 years old.
Bob is 17 years old.
David is 22 years old.
Andy is 25 years old.
Charlie is 25 years old.
Alice is 35 years old.
Jessie is 35 years old.
Mark is 35 years old.
- 따로 클래스를 만들어서 사용하는 경우 정렬 기준(
Comparable,Comparator)을 구현해야 함-
equals과hashCode도 구현
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class TreeSetMain2 {
public static void main(String[] args) {
// 1. 들어갈 데이터가 Integer인 TreeSet 생성
TreeSet<Integer> treeSet = new TreeSet<>();
// 2. TreeSet에 요소 추가
treeSet.add(5);
treeSet.add(2);
treeSet.add(8);
treeSet.add(1);
treeSet.add(3);
treeSet.add(6);
treeSet.add(5); // 중복 추가해도 추가되지 않음
// 3. TreeSet의 요소 출력해보기 - 정렬되어 있는 것을 확인할 수 있음
for (Integer i : treeSet) {
System.out.println(i);
}
// 4. 가장 첫 요소(가장 작은 요소) 출력
System.out.println("First Element: "+treeSet.first());
// 5. 가장 마지막 요소(가장 큰 요소) 출력
System.out.println("Last Element: "+treeSet.last());
// 6. 주어진 기준(3) 보다 큰 요소 중에 제일 작은 요소 출력
System.out.println("Element higher than 3: "+treeSet.higher(3));
// 7. subSet() - 주어진 범위내의 집합
System.out.println("treeSet.subSet(2,6) = "+treeSet.subSet(2,6)); // 2이상 6미만
// 8. headSet() - 주어진 기준(5) 미만의 집합
System.out.println("treeSet.headSet(5) = "+treeSet.headSet(5));
// 9. tailSet() - 주어진 기준(6) 이상의 집합
System.out.println("treeSet.tailSet(6) = "+treeSet.tailSet(6));
}
}
1
2
3
4
5
6
7
8
9
10
11
12
1
2
3
5
6
8
First Element: 1
Last Element: 8
Element higher than 3: 5
treeSet.subSet(2,6) = [2, 3, 5]
treeSet.headSet(5) = [1, 2, 3]
treeSet.tailSet(6) = [6, 8]
6) Map
- 순서가 없고, 키의 중복은 허용하지 않는다 (값의 중복은 가능)
- 순서 유지가 필요하다면
LinkedHashMap사용
- 순서 유지가 필요하다면
- Key-Value 쌍으로 데이터 저장
-
HashTable은 동기화 되어있음 (Synchronization o)- 지금은
HashTable은 거의 사용하지 않고ConcurrentHashMap사용
- 지금은
-
HashMap은 동기화 되어있지 않음 (Synchronization x) -
TreeMap은 이진 탐색 트리의 속성을 가지고 있음 - Hashing
- 해쉬 함수(hash function)로 해시 테이블(hash table)에 데이터를 저장하고 검색
- 해시 테이블은 배열과 링크드 리스트가 조합된 형태 (사전 비슷하게 생각하면 됨)
6.1 HashMap
- 보통
HashMap을 많이 사용함 -
HashMap은 동기화 되어있지 않음 (Synchronization x) - single-thread에서 더 좋은 성능
- 하나의
nullkey 가능, 복수의nullvalue 허용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
public class HashMapMain {
public static void main(String[] args) {
// HashMap 생성 - student(key) : grade(value)
Map<String, Integer> studentGrades = new HashMap<>();
// 1. put() - Add entries to the HashMap
studentGrades.put("Alice", 90);
studentGrades.put("Bob", 85);
studentGrades.put("Charlie", 92);
studentGrades.put("David", 88);
// 2. HashMap의 Key-Value 출력해보기
System.out.println("-----------print entries of HashMap------------");
for (Map.Entry<String, Integer> entry : studentGrades.entrySet()) {
System.out.println("Key: "+entry.getKey()+", Value: "+entry.getValue());
}
// 2. get() - Retrieve the grade for a specific student
System.out.println("-------retrieve value of a specific key--------");
int charlieGrade = studentGrades.get("Charlie");
System.out.println("Charlie's Grade: " + charlieGrade);
// 3. containsKey() - Check if the HashMap contains a specific key
System.out.println("-----------------------------------------------");
boolean hasAlice = studentGrades.containsKey("Alice");
System.out.println("Does it contain Alice?: " + hasAlice);
// 4. size() - Get the number of entries in the HashMap
int numberOfStudents = studentGrades.size();
System.out.println("Number of Students: " + numberOfStudents);
// 5. keySet() - Get a set of all keys in the HashMap
System.out.println("Students: " + studentGrades.keySet());
// 6. values() - Get a collection of all values in the HashMap
System.out.println("Grades: " + studentGrades.values());
// 7. entrySet() - Get a set of key-value pairs (entries) in the HashMap
System.out.println("Entries: " + studentGrades.entrySet());
// 8. remove() - Remove a specific entry from the HashMap
studentGrades.remove("Bob");
System.out.println("HashMap after removing Bob: " + studentGrades);
// 9. clear() - Remove all entries from the HashMap
studentGrades.clear();
System.out.println("HashMap after clearing: " + studentGrades);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-----------print entries of HashMap------------
Key: Bob, Value: 85
Key: Alice, Value: 90
Key: Charlie, Value: 92
Key: David, Value: 88
-------retrieve value of a specific key--------
Charlie's Grade: 92
-----------------------------------------------
Does it contain Alice?: true
Number of Students: 4
Students: [Bob, Alice, Charlie, David]
Grades: [85, 90, 92, 88]
Entries: [Bob=85, Alice=90, Charlie=92, David=88]
HashMap after removing Bob: {Alice=90, Charlie=92, David=88}
HashMap after clearing: {}
7) Stack, Queue, ArrayDeque
-
Stack: Last in First Out (LIFO) Queue: First in First Out (FIFO)-
ArrayDeque는Stack,Queue의 기능 모두 포함- 내부적으로
Vector를 이용해서 구현된Stack은 사실상 deprecated
- 내부적으로
- Java docs -
ArrayDeque
7.1 ArrayDeque
- 실무에서는 대부분
ArrayDeque사용 - 양 끝에서 삽입과 반환이 가능함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
public class ArrayDequeMain {
public static void main(String[] args) {
// ArrayDeque 생성
ArrayDeque<String> taskQueue = new ArrayDeque<>();
// 1. addFirst(), addLast() 사용
// addFirst() - 요소를 앞에서 부터 삽입
System.out.println("---------Using addFirst(), addLast()---------");
taskQueue.addFirst("Task 1");
taskQueue.addFirst("Task 2");
// addLast() - 요소를 뒤에서 부터 삽입
taskQueue.addLast("Task 3");
taskQueue.addLast("Task 4");
// deque 출력
System.out.println(taskQueue);
// deque 비우기
taskQueue.clear();
// 2. offerFirst(), offerLast() 사용
// 요소를 삽입하는 동작 자체는 addFirst, addLast와 똑같음
System.out.println("-------Using offerFirst(), offerLast()-------");
taskQueue.offerFirst("Task A");
taskQueue.offerFirst("Task B");
taskQueue.offerLast("Task C");
taskQueue.offerLast("Task D");
System.out.println(taskQueue);
taskQueue.clear();
// 3. push, pop 사용
System.out.println("-------Using push()-------");
// push()는 요소를 앞에 삽입
taskQueue.push("Urgent Task 1");
taskQueue.push("Urgent Task 2");
System.out.println(taskQueue);
// pop()은 앞의 요소 제거 후 반환
System.out.println("The returned element after pop(): "+taskQueue.pop());
System.out.println("The returned element after pop(): "+taskQueue.pop());
System.out.println("-------After pop()-------");
System.out.println(taskQueue);
}
}
1
2
3
4
5
6
7
8
9
10
---------Using addFirst(), addLast()---------
[Task 2, Task 1, Task 3, Task 4]
-------Using offerFirst(), offerLast()-------
[Task B, Task A, Task C, Task D]
-------Using push()-------
[Urgent Task 2, Urgent Task 1]
The returned element after pop(): Urgent Task 2
The returned element after pop(): Urgent Task 1
-------After pop()-------
[]
-
offerFirst,offerLast는addFirst,addLast와 다르게 큐의 크기 문제가 발생시false를 반환한다. (addFirst는IllegalStateException)
IllegalStateException- if the element cannot be added at this time due to capacity restrictions
8) Comparable, Comparator
- 객체를 비교하기 위해서 사용(정렬 기준을 제시)
-
sort()디폴트는 오름차순 -
Comparable또는Comparator를 구현해서 사용자가 정한 기준을 토대로 양수, 0, 음수 중 하나가 반환 → 정렬 기준에 사용
8.1 Comparator
배열을 정렬하는 하는 상황이라고 가정해보자. 정렬을 하기 위해서는 sort()를 사용할 때 Comparator(비교자)를 넘겨줘서 정렬을 할 수 있다.
넘겨주는 비교자는 Comparator 인터페이스를 구현하면 된다.
1
2
3
public interface Comparator<T> {
int compare(T o1, T o2);
}
- 두 인수를 비교해서 결과값을 반환하면 된다
- 첫 번째 인수가 더 작으면
음수 - 두 값이 같으면
0 - 첫 번째 인수가 더 크면
양수
- 첫 번째 인수가 더 작으면
그러면 정렬을 해보자.
SortMain1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
public class SortMain1 {
public static void main(String[] args) {
Integer[] array = {4, 3, 2, 1};
System.out.println("array = " + Arrays.toString(array));
// AscComparator를 제공해서 오름차순 정렬
Arrays.sort(array, new AscComparator());
System.out.println("AscComparator : " + Arrays.toString(array));
// DescComparator를 제공해서 내림차순 정렬
Arrays.sort(array, new DescComparator());
System.out.println("DescComparator : " + Arrays.toString(array));
// AscComparator.reversed()를 사용해서 내림차순 정렬 가능
array = new Integer[]{4, 3, 2, 1};
Arrays.sort(array, new AscComparator().reversed());
System.out.println("AscComparator().reversed() : " + Arrays.toString(array));
}
// 오름차순 정렬을 위한 Comparator 구현
static class AscComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
// System.out.println("o1 = " + o1 + ", o2 = " + o2);
return (o1 < o2) ? -1 : ((o1.equals(o2)) ? 0 : 1);
}
}
// 내림차순 정렬을 위한 Comparator 구현
static class DescComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
// System.out.println("o1 = " + o1 + ", o2 = " + o2);
return (o1 < o2) ? -1 : ((o1.equals(o2)) ? 0 : 1) * -1;
}
}
}
1
2
3
4
array = [4, 3, 2, 1]
AscComparator : [1, 2, 3, 4]
DescComparator : [4, 3, 2, 1]
AscComparator().reversed() : [4, 3, 2, 1]
-
Arrays.sort()를 사용할 때 비교자(Comparator)를 제공하면 알고리즘에서 어떤 값이 더 큰지 두 값을 비교할 때 비교자를 사용한다 - 반대의 정렬을 하고 싶으면 간단하게
.reversed()를 사용할 수 있다
여기서 이런 의문을 가지는 사람이 있을 수 있다. 분명 다른 코드에서는 Comparator를 넘기지 않고 단순히 .sort(array) 같은 형식으로 오름차순 정렬을 할 수 있던걸로 기억하는데, 이게 어떻게 가능하지 궁금할 것이다.
먼저 다음 코드를 살펴보자.
SortMain2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class SortMain2 {
public static void main(String[] args) {
Integer[] array = {2, 1, 3, 4};
System.out.println("array = " + Arrays.toString(array));
// 오름차순 정렬
Arrays.sort(array);
System.out.println(".sort(array) : " + Arrays.toString(array));
// 내림차순 정렬
Arrays.sort(array, reverseOrder());
System.out.println(".sort(array, Comparator.reverseOrder()) : " + Arrays.toString(array));
}
}
1
2
3
array = [2, 1, 3, 4]
.sort(array) : [1, 2, 3, 4]
.sort(array, Comparator.reverseOrder()) : [4, 3, 2, 1]
-
Comparator를 제공하지 않고sort()를 사용해도 오름차순 정렬이 되는 것을 확인할 수 있다. 이 이유는 별도의 비교자를 제공하지 않으면, 객체의 구현된Comparable을 이용하기 때문이다.
우리가 사용한 Integer는 Comparable이 오름차순으로 정렬하도록 기본적으로 구현되어 있다. 이 Comparable을 통해 구현한 순서를 객체의 자연 순서(Natural Ordering)이라고 한다.
8.2 Comparable
바로 이전에 설명했던 것 처럼 객체의 Comparable 인터페이스를 구현하면, 해당 Comparable이 객체의 디폴트 정렬 방식이 된다. 이런 디폴트 정렬 방식을 자연 순서(Natural Ordering)라고 한다.
어떤 객체를 정렬하기 위해서는 비교자(Comparator)를 제공하거나, Comparable 인터페이스를 구현하고 있어야한다.
아무튼 이 Comparable 인터페이스를 구현해서 사용하면 사용자 정의 객체를 객체의 특정 필드를 기준으로 비교할 수 있게된다. 코드를 통해 살펴보자.
1
2
3
public interface Comparable<T> {
public int compareTo(T o);
}
- 자기 자신과 인수로 넘어온 객체를 비교해서 반환하면 된다
- 현재 객체가 인수로 주어진 객체보다 저 작으면
음수 - 두 객체의 크기가 같으면
0 - 현재 객체가 인수로 주어진 객체보다 크면
양수
- 현재 객체가 인수로 주어진 객체보다 저 작으면
Comparable을 구현할 클래스를 만들어보자.
Employee
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public class Employee implements Comparable<Employee> {
private String id;
private int age;
public Employee(String id, int age) {
this.id = id;
this.age = age;
}
public String getId() {
return id;
}
public int getAge() {
return age;
}
// Comparable 구현 - age를 기준으로 오름차순 정렬
@Override
public int compareTo(Employee o) {
return this.age < o.age ? -1 : (this.age == o.age ? 0 : 1);
}
@Override
public String toString() {
return "Customer{" +
"id='" + id + '\'' +
", age=" + age +
'}';
}
}
-
Employee객체를sort()를 통해 정렬할 때 비교자를 제공하지 않으면 구현된Comparable의 기준을 통해 정렬이 된다 - 위의
Employee의 경우age를 기준으로 오름차순 정렬하는 것이 자연 순서
한번 정렬된 결과를 확인해보자.
ComparableMain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class ComparableMain {
public static void main(String[] args) {
Employee employee1 = new Employee("김부장", 50);
Employee employee2 = new Employee("박과장", 30);
Employee employee3 = new Employee("최사원", 20);
List<Employee> employees = new ArrayList<>(Arrays.asList(employee1, employee2, employee3));
System.out.println("employees = " + employees);
// Comparable을 이용한 디폴트 정렬
// 이 경우에는 age를 기준으로 오름차순 정렬
employees.sort(null);
System.out.println("employees = " + employees);
}
}
1
2
3
employees = [Customer{id='김부장', age=50}, Customer{id='박과장', age=30}, Customer{id='최사원', age=20}]
employees = [Customer{id='최사원', age=20}, Customer{id='박과장', age=30}, Customer{id='김부장', age=50}]
이제 Comparator를 다시 한번 사용해보자. 이전에도 설명했지만 Comparator를 제공해서 정렬 기준을 세울 수 있다. 현재 케이스에 적용해보자면, age를 기준으로 오름차순 정렬하는 Comparable을 이용하지 않고 id를 기준으로 정렬하고 싶다면, 이 때 Comparator를 구현해서 제공하면 되는 것이다.
코드를 통해 살펴보자.
id로 비교할 수 있는 비교자인 IdComparator를 만들어보자.
IdComparator
1
2
3
4
5
6
7
8
9
public class IdComparator implements Comparator<Employee> {
// Employee의 객체의 id를 기준으로 오름차순 정렬
// String 같은 클래스는 전부 compareTo() 같은 메서드들이 전부 구현되어 있다
@Override
public int compare(Employee o1, Employee o2) {
return o1.getId().compareTo(o2.getId());
}
}
-
Comparator인터페이스를 구현해서 비교자를 만들었다 -
id기준으로 오름차순 정렬
IdComparator를 이용해보자.
ComparatorMain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class ComparatorMain {
public static void main(String[] args) {
Employee employee1 = new Employee("Amy", 50);
Employee employee2 = new Employee("Bob", 30);
Employee employee3 = new Employee("Cindy", 20);
List<Employee> employees = new ArrayList<>(Arrays.asList(employee3, employee2, employee1));
System.out.println("employees = " + employees);
// Comparator를 이용한 정렬
// id를 기준으로 오름차순 정렬
employees.sort(new IdComparator());
System.out.println("IdComparator() : " + employees);
// 반대로 정렬
employees.sort(new IdComparator().reversed());
System.out.println("IdComparator().reversed() : " + employees);
}
}
1
2
3
4
5
employees = [Customer{id='Cindy', age=20}, Customer{id='Bob', age=30}, Customer{id='Amy', age=50}]
IdComparator() : [Customer{id='Amy', age=50}, Customer{id='Bob', age=30}, Customer{id='Cindy', age=20}]
IdComparator().reversed() : [Customer{id='Cindy', age=20}, Customer{id='Bob', age=30}, Customer{id='Amy', age=50}]
-
sort()에 비교자를 제공해서 정렬 기준으로 사용할 수 있다 -
Collections.sort()를 이용할 수 있지만, 객체 스스로가 가지는 정렬 메서드를 활용하는 것을 권장한다
이전에도 언급했지만
Comparable도 구현하지않고Comparator도 제공하지 않은 상태로 정렬을 시도하면 런타임 오류가 발생한다!
8.3 Comparable, Comparator 예시
Comparable을 다시 한번 사용해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
class Fruit implements Comparable<Fruit> {
private String name;
private int quantity;
public Fruit(String name, int quantity) {
this.name = name;
this.quantity = quantity;
}
// Implement compareTo method for natural ordering(오름차순)
@Override
public int compareTo(Fruit other) {
// 자기 자신의 quantity와 넘긴 매개변수 객체의 quantity 비교
/*
if(this.quantity > other.quantity) {
return 1;
} else if (this.quantity == other.quantity) {
return 0;
} else {
return -1;
}
*/
return this.quantity - other.quantity; // 범위 넘어가는 경우 주의
// 내림차순으로 정렬하고 싶은 경우
// return -(this.quantity - other.quantity);
}
@Override
public String toString() {
return "Fruit{name='" + name + "', quantity=" + quantity + '}';
}
}
public class ComparableMain {
public static void main(String[] args) {
List<Fruit> fruits = new ArrayList<>();
fruits.add(new Fruit("Apple", 10));
fruits.add(new Fruit("Banana", 5));
fruits.add(new Fruit("Orange", 8));
fruits.add(new Fruit("Orange", 2));
// Sort using natural ordering (compareTo method)
Collections.sort(fruits);
// Print sorted list
for (Fruit fruit : fruits) {
System.out.println(fruit);
}
}
}
1
2
3
4
Fruit{name='Orange', quantity=2}
Fruit{name='Banana', quantity=5}
Fruit{name='Orange', quantity=8}
Fruit{name='Apple', quantity=10}
-
compareTo를 구현할 때 두 값을 빼는 경우, 타입 범위를 넘어서는 것을 주의하자- 필요한 경우 그냥
if-else문으로 구현
- 필요한 경우 그냥
- 만약
quantity가 아니라name의 사전순서로 정렬하는 경우
1
2
3
4
@Override
public int compareTo(Fruit other) {
return this.name.compareTo(other.name); // String의 compareTo()를 사용
}
1
2
3
4
Fruit{name='Apple', quantity=10}
Fruit{name='Banana', quantity=5}
Fruit{name='Orange', quantity=8}
Fruit{name='Orange', quantity=2}
Comparator를 사용해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
class Fruit2 {
private String name;
int quantity; // 편의상 private 생략, 원래는 get 메서드를 정의해서 데이터를 접근해야함
public Fruit2(String name, int quantity) {
this.name = name;
this.quantity = quantity;
}
@Override
public String toString() {
return "Fruit{name='" + name + "', quantity=" + quantity + '}';
}
}
public class ComparatorMain {
public static void main(String[] args) {
List<Fruit2> fruits = new ArrayList<>();
fruits.add(new Fruit2("Apple", 10));
fruits.add(new Fruit2("Grape", 19));
fruits.add(new Fruit2("Banana", 5));
fruits.add(new Fruit2("Orange", 8));
fruits.add(new Fruit2("Orange", 2));
Collections.sort(fruits, comparator); // 아래에서 정의한 comparator 사용
// Print sorted list
for (Fruit2 fruit : fruits) {
System.out.println(fruit);
}
}
// 익명 클래스를 사용해서 Comparator의 기능 사용
public static Comparator<Fruit2> comparator = new Comparator<Fruit2>() {
@Override
public int compare(Fruit2 o1, Fruit2 o2) {
return o1.quantity - o2.quantity; // 오름차순 정렬 가능
// return (o1.name1).compareTo(o2.name2) // name을 기준으로
}
};
// 익명 클래스 하나더 생성해서 사용가능
public static Comparator<Fruit2> comparator2 = new Comparator<Fruit2>() {
@Override
public int compare(Fruit2 o1, Fruit2 o2) {
return -(o1.quantity - o2.quantity); // 내림차순 정렬 가능
}
};
}
1
2
3
4
5
Fruit{name='Orange', quantity=2}
Fruit{name='Banana', quantity=5}
Fruit{name='Orange', quantity=8}
Fruit{name='Apple', quantity=10}
Fruit{name='Grape', quantity=19}
9) 컬렉션 유틸(Collections)
컬렉션을 편리하게 다룰 수 있는 유틸에 대해 알아보자.
9.1 정렬, 최대값, 최소값
코드로 바로 알아보자.
CollectionsMain1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public class CollectionsMain1 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Integer max = Collections.max(list);
Integer min = Collections.min(list);
System.out.println("min = " + min);
System.out.println("max = " + max);
System.out.println("list = " + list);
// 리스트 랜덤으로 섞기
Collections.shuffle(list);
System.out.println("shuffle list = " + list);
// 정렬
// Comparator 제공 가능
Collections.sort(list);
System.out.println("sort list = " + list);
// 역정렬
Collections.reverse(list);
System.out.println("reverse list = " + list);
}
}
1
2
3
4
5
6
min = 1
max = 5
list = [1, 2, 3, 4, 5]
shuffle list = [5, 4, 1, 3, 2]
sort list = [1, 2, 3, 4, 5]
reverse list = [5, 4, 3, 2, 1]
9.2 컬렉션 생성
코드로 바로 알아보자.
ImmutableMain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class ImmutableMain {
public static void main(String[] args) {
// 불변 컬렉션 생성
// 변경 불가!
List<Integer> list = List.of(1, 2, 3, 4);
Set<Integer> set = Set.of(1, 2, 3, 4);
Map<String, Integer> map = Map.of("A", 1, "B", 2);
System.out.println("list = " + list);
System.out.println("set = " + set);
System.out.println("map = " + map);
// java.lang.UnsupportedOperationException 발생
// list.add(5);
}
}
1
2
3
list = [1, 2, 3, 4]
set = [1, 2, 3, 4]
map = {A=1, B=2}
-
.of(...)- 컬렉션을 편리하게 생성
- 불변 컬렉션(immutable)으로 생성됨
- 불변이기 때문에 어떤 변경을 가하는 작업은 불가능 함
- 자바 9 부터 지원하는 기능이다. 만약 자바 8을 사용한다면 뒤에서 다룰
asList()를 사용하거나, 다른 방법을 사용해야 한다. -
of()같은 형태로 사용해서 빈 컬렉션을 만들 수 있다-
emptyList()를 사용할 수도 있으나, 만약 자바9 이상을 사용한다면of()를 사용하는 것을 권장한다
-
그럼 위의 불변 컬렉션을 가변으로 변환하는 방법을 코드로 알아보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class ToMutableMain {
public static void main(String[] args) {
// 불변 리스트 생성
List<Integer> list = List.of(1, 2, 3, 4); // add()와 같은 변경 불가
System.out.println("immutable list = " + list);
// 가변 리스트로 변환
ArrayList<Integer> mutableList = new ArrayList<>(list); // 변경 가능
mutableList.add(5);
System.out.println("mutableList = " + mutableList);
// 다시 불변 리스트로 변환
List<Integer> unmodifiableList = Collections.unmodifiableList(mutableList); // 불변 리스트
System.out.println("unmodifiableList.getClass() = " + unmodifiableList.getClass());
}
}
1
2
3
immutable list = [1, 2, 3, 4]
mutableList = [1, 2, 3, 4, 5]
unmodifiableList.getClass() = class java.util.Collections$UnmodifiableRandomAccessList
이번에는 asList()에 대해 알아보자.
AsListMain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class AsListMain {
public static void main(String[] args) {
// asList()를 사용하면 고정된 크기를 가지는 리스트를 생성한다.(길이 변경 불가)
// 그렇다고 불변이라는 뜻은 아니다. 요소를 변경하는 것은 가능하다.
List<Integer> list = Arrays.asList(1, 2, 3, 4);
System.out.println("list = " + list);
// 요소 변경
list.set(3, 100);
System.out.println("list = " + list);
// 요소 추가/삭제는 불가능
// list.add(5);
}
}
1
2
list = [1, 2, 3, 4]
list = [1, 2, 3, 100]
-
asList()은 사용하기 애매함. 보통은of()사용을 권장. -
asList()를 사용하는 경우- 자바9 하위 버전을 사용하는 경우
- 리스트의 크기는 변경하지 않으면서 내부의 요소를 변경하는 경우
9.3 멀티스레드 동기화(synchronizedXxx())
멀티스레드 상황에서 동기화 문제가 발생하지 않도록 컬렉션을 변경하는 방법에 대해 알아보자.
1
2
ArrayList<Integer> list = new ArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(list);
-
Collections.synchronizedList를 사용하면 일반 리스트를 멀티스레드 상황에서 동기화 문제가 발생하지 않도록 스레드 안전한(thread-safe) 리스트로 만들 수 있다 - 보통 동기화 작업으로 인해 성능은 일반 리스트에 비해 느리다
-
synchronizedList()외에도 다양한synchronizedXxx()를 제공한다 - 성능에 따라 특정 상황에서는
CopyOnWriteArrayList같은CopyOnWrite컬렉션을 사용하거나,ConcurrentHashMap과 같은Concurrent컬렉션을 사용할 수 있다
멀티스레드에 상황에서의 컬렉션은 멀티스레드 개념을 충분히 알고 있어야하기 때문에, 이후에 더 깊게 다룰 예정이다.
Comments powered by Disqus.