1. 스트림(Stream)
스트림 소개
스트림(Stream)에 대해서 알아보자. 스트림은 말 그대로 데이터의 흐름이다. 스트림은 다양한 데이터 소스를 함수형(functional) 또는 선언적인(declarative) 방법으로 다루기 위한 인터페이스이다.
여기서 다양한 데이터 소스는 다음을 포함한다.
-
List, Set, Map 등의 컬렉션
- 배열
- I/O channel
- generator function
- 기타의 다양한 데이터 소스
스트림의 과정을 살펴보면 다음과 같다.
https://innovationm.co/concept-of-stream-api-java1-8/
-
스트림 생성
-
중간 연산(Intermediate operations)
- 중간 연산을 수행한다
- 중간 연산은 반복적 수행이 가능하다
-
최종 연산(Terminal operation)
- 최종 연산을 수행한다
- 최종 연산은 단 1번만 수행한다
- 최종 연산을 통해서 결과가 만들어진다
스트림의 연산 과정
스트림의 특징
스트림의 특징에 대해서 알아보자.
읽기만 함(read-only)
스트림은 데이터 소스로 부터 데이터를 읽기만 하고, 원본 데이터는 변경하지는 않는다.
1
2
3
4
5
6
7
8
|
// 스트림은 Read only (데이터 소스 변경 x)
List<Integer> list = Arrays.asList(3, 1, 5, 4, 2); // 데이터 소스
List<Integer> sortedList = list.stream().sorted() // list 정렬
.collect(Collectors.toList()); // 새로운 sortedList에 저장
System.out.println(list); // [3, 1, 5, 4, 2]
System.out.println(sortedList); // [1, 2, 3, 4, 5]
|
1
2
|
[3, 1, 5, 4, 2]
[1, 2, 3, 4, 5]
|
한번만 사용
스트림은 일회용이다. 다시 필요하면 스트림을 다시 생성해서 사용해야 한다.
1
2
3
|
strStream.forEach(System.out::println); // 모든 요소를 화면에 출력하는 최종 연산(스트림이 닫힌다)
int numOfStr = strStream.count(); // 스트림이 닫혀서 에러!
|
지연 연산(lazy evaluation)
스트림은 지연연산(Lazy evaluation)을 사용한다. 즉, 최종 연산 전까지 중간 연산이 수행되지 않는다. 쉽게 말해서 결과값이 필요할 때 까지 모든 연산을 늦춘다.
1
2
3
4
|
Stream<Integer> evenNumbers = Stream.iterate(0, n -> n + 2)
.limit(5); // 최종 연산이 수행될 때 까지 연산을 수행하지 않는다
// 생략 ..
evenNumbers.forEach(System.out::println); // 최종 연산에서 연산 수행
|
내부 반복
스트림은 내부 반복을 포함한다. Java의 스트림 API에서 반복 처리는 내부적으로 관리되며, 개발자는 어떻게 반복이 이루어지는지 신경 쓸 필요가 없다.
1
2
3
4
|
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.stream() // 스트림 생성
.filter(name -> name.startsWith("A")) // 어떻게 처리할지 조건을 정의한 중간 연산으로 보면 된다
.forEach(System.out::println); // 최종 연산: 실제로 연산이 진행. 내부적으로 리스트의 각 요소를 하나씩 꺼내서 filter()와 forEach()를 적용한다. 바로 뒤에서 자세히 알아볼 것이다
|
실행 순서: 단일 요소 처리
스트림의 단일 요소 처리는 스트림 API의 중요한 특징 중 하나로, 각 요소를 하나씩 순차적으로 처리하는 방식을 의미한다. 즉, 한 번에 하나의 요소를 중간 연산과 최종 연산에서 처리하는 방식이다.
1
2
3
4
5
6
7
8
9
10
11
12
|
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eve");
names.stream()
.filter(name -> {
System.out.println("Filtering: " + name);
return name.startsWith("A");
})
.map(name -> {
System.out.println("Mapping: " + name);
return name.toUpperCase();
})
.forEach(name -> System.out.println("Final result: " + name));
|
1
2
3
4
5
6
7
|
Filtering: Alice
Mapping: Alice
Final result: ALICE
Filtering: Bob
Filtering: Charlie
Filtering: David
Filtering: Eve
|
- 첫 번째 요소인
Alice가 먼저 스트림에 들어간다. filter()에서 Alice는 조건을 만족하므로 true를 반환하고 다음 연산으로 넘어간다. 그래서 map()과 forEach() 연산에서 Alice와 ALICE가 출력될 수 있는 것이다.
- 그 다음에서야
Bob이 스트림에 들어가고, Bob에 대해서 각 연산이 실행되고 Charlie가 스트림에 들어가는 방식으로 진행된다
스트림을 사용하지 않는 외부 반복문을 사용했다면, 각 연산에 대해 Alice ~ Eve 까지 전부 한번에 처리하는 방식으로 동작했을 것이다.
병렬 스트림(parallel stream)
일반적으로 스트림은 순차적으로 데이터를 처리한다. 즉, 각 요소는 하나씩 순차적으로 처리되며, 한 요소에 대한 처리가 끝난 후 다음 요소가 처리된다. 하지만 병렬 스트림을 사용하면 데이터를 여러 스레드에서 병렬로 나누어 처리함으로써 작업을 분산시킬 수 있다. 이는 대용량의 데이터를 처리할 때 효과적일 수 있다.
병렬 스트림의 특징은 다음과 같다.
-
ForkJoinPool 사용: 병렬 스트림은 내부적으로 ForkJoinPool을 사용하여 작업을 여러 개의 스레드로 분할한다
-
데이터 분할: 병렬 스트림은 데이터를 덩어리(chunk)로 나누어 여러 스레드가 병렬로 작업할 수 있게 만든다. 즉, 각 스레드는 데이터의 일부 청크를 처리하고, 모든 스레드의 작업이 끝나면 결과가 결합된다.
-
병렬 처리의 자동 관리: 병렬 스트림은 스레드 생성과 작업 분배를 자동으로 처리한다. 개발자가 수동으로 스레드를 만들거나 관리할 필요가 없으며, 스트림 API가 병렬 처리를 자동으로 최적화한다.
-
순서 보장 없음: 병렬 스트림에서 각 스레드는 동시에 작업을 수행하므로, 출력 순서가 보장되지 않는다. 데이터를 처리하는 순서와 출력되는 순서는 다를 수 있다. 순서가 중요한 경우에는
forEachOrdered()와 같은 연산을 사용할 수 있다.
병렬 스트림은 parallelStream()을 사용하여 생성할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eve");
// 1. 순차 스트림
System.out.println("---순차 스트림(순서 보장 o)---");
names.stream()
.filter(name -> name.length() > 3)
.forEach(System.out::println);
// 2. 병렬 스트림
System.out.println("---병렬 스트림(순서 보장 x)---");
names.parallelStream()
.filter(name -> name.length() > 3)
.forEach(System.out::println);
|
1
2
3
4
5
6
7
8
|
---순차 스트림(순서 보장 o)---
Alice
Charlie
David
---병렬 스트림(순서 보장 x)---
Charlie
David
Alice
|
-
sequential()을 사용해서 다시 순차 스트림으로 전환할 수 있다(모든 컬렉션 스트림은 기본적으로 순차 스트림이다)
병렬 스트림 주의점
-
데이터 정합성 문제
병렬 스트림은 여러 스레드에서 동시에 데이터를 처리하므로, 공유 자원에 접근하는 경우 동시성 문제(예: race condition)가 발생할 수 있다
예: forEach() 같은 메서드에서 외부 변수를 수정하는 경우 문제가 발생할 수 있다
1
2
3
4
|
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int[] sum = {0};
numbers.parallelStream().forEach(n -> sum[0] += n); // 위험한 코드
|
-
성능 저하
- 병렬 스트림은 작은 데이터 세트에서는 오히려 성능 저하를 일으킬 수 있다
- 병렬 처리의 오버헤드(스레드 생성, 컨텍스트 스위칭 등)로 인해 순차 처리보다 느릴 수 있기 때문이다
- 대용량 데이터나 CPU 집약적인 작업인지 판단 후에 성능을 측정해서 사용하는 것을 권장한다
기본형 스트림(primitive stream)
스트림 API는 기본형 스트림을 지원하여 성능을 최적화하고, 객체로 변환하는 오버헤드를 줄일 수 있다. Java에서는 모든 데이터가 객체로 처리되기 때문에 기본형인 int, long, double 등을 사용할 때 객체화(박싱, unboxing) 과정이 발생한다. 이런 과정을 줄이고 성능을 높이기 위해 기본형 스트림이 제공된다.
1
2
3
4
5
6
7
8
9
10
11
|
// IntStream
IntStream.range(1, 6).forEach(System.out::println); // 1, 2, 3, 4, 5
int intSum = IntStream.rangeClosed(1, 5).sum(); // 1~5까지의 합
// LongStream
LongStream.of(100L, 200L, 300L).forEach(System.out::println); // 100, 200, 300
long longSum = LongStream.of(100L, 200L, 300L).sum(); // 합
// DoubleStream
DoubleStream.of(1.5, 2.5, 3.5).forEach(System.out::println); // 1.5, 2.5, 3.5
double doubleSum = DoubleStream.of(1.5, 2.5, 3.5).sum(); // 합
|
- 래퍼 클래스의 오토박싱, 언박싱의 비효율이 제거된다. 이런 특징은 대규모 데이터를 다룰때 성능상 이점을 제공할 수 있다. 물론 성능의 측정을 권장한다.
- 예:
Stream<Integer> 대신 IntStream 사용
기본형 스트림은 다양한 연산을 제공한다.
-
sum(): 스트림의 요소들의 합
-
average(): 요소들의 평균값 반환
-
max(), min(): 최대값, 최소값 반환
boxed()를 사용해서 기본형 스트림을 대응하는 래퍼 타입의 객체 스트림으로 변환하는 것이 가능하다.
1
2
3
|
IntStream intStream = IntStream.range(1, 5);
Stream<Integer> boxedStream = intStream.boxed(); // int를 Integer로 변환
boxedStream.forEach(System.out::println);
|
2. 스트림 생성
본격적으로 스트림의 사용법에 대해 알아보자.
컬렉션(Collection)
Collection 인터페이스의 stream()으로 컬렉션을 데이터 소스로 하는 스트림을 생성해보자.
1
2
3
4
|
List<Integer> list = Arrays.asList(3, 1, 5, 4, 2);
Stream<Integer> integerStream = list.stream(); // list를 데이터 소스로 하는 스트림 생성
integerStream.forEach(System.out::print); // 최종 연산(스트림 닫힘)
|
배열(Array)
배열로 부터 스트림을 생성해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// 1. 객체 배열로 부터 스트림 생성하기
// Stream<T> Stream.of(v1, v2, .. vn)
Stream<String> stringStream1 = Stream.of("A", "B", "C");
stringStream1.forEach(System.out::print); // ABC
// Stream<T> Stream.of(T[])
Stream<String> stringStream2 = Stream.of(new String[]{"A", "B", "C"});
stringStream2.forEach(System.out::print); // ABC
// Stream<T> Arrays.stream(T[])
String[] strArr = {"A", "B", "C"};
Stream<String> stringStream3 = Arrays.stream(strArr);
stringStream3.forEach(System.out::print); // ABC
// 2. 기본형 배열로 부터 스트림 생성하기
int[] intArr = {10, 20, 30, 40};
IntStream intStream = Arrays.stream(intArr);
intStream.forEach(System.out::print); //10203040
// Stream<Integer>를 사용하고 싶으면 int[] -> Integer[] 사용한다
Integer[] integers = {10, 20, 30, 40};
Stream<Integer> intStream2 = Arrays.stream(integers);
intStream2.forEach(System.out::print); // 10203040
|
난수, 기본형 스트림
난수를 요소로 갖는 스트림을 생성해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 1. 난수
// limit
IntStream intStream = new Random().ints(); // 무한 스트림이 생성 됨
intStream.limit(4).forEach(System.out::println); // 4개의 요소만 출력하도록 limit 사용
// limit 사용하지 않고 유한 스트림으로
IntStream intStream2 = new Random().ints(4); // 4개만
intStream2.forEach(System.out::println);
// 난수의 범위 지정
IntStream intStream3 = new Random().ints(0, 100); // 범위 : 0~99
intStream3.limit(4).forEach(System.out::println);
// 2. 기본형 스트림: 특정 범위의 정수를 요소로 갖는 스트림
// IntStream
IntStream intStream4 = IntStream.range(1, 10); // 범위 : 1~9
// 끝의 수 까지 포함하고 싶으면 rangeClosed() 사용
intStream4.forEach(System.out::print); // 123456789
|
iterate()
1
|
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) // 이전 요소에 종속적
|
- 첫 번째 인자는 시드 값(초기값)을 받는다
- 두 번째 인자는
UnaryOperator<T> 타입의 람다식을 받는다
iterate()는 시드 값(초기값)을 시작으로, 주어진 람다식에 의해 생성된 값들을 소스로 무한 또는 유한한 스트림을 만든다. 이때, 람다식은 이전 요소를 기반으로 다음 요소를 생성하는 역할을 한다. 즉, 람다식이 값을 계산하는 규칙을 제공하는 것으로 보면 된다.
1
2
3
|
Stream<Integer> evenNumbers = Stream.iterate(0, n -> n + 2) // 0부터 시작, 람다식 계산은 2씩 증가
.limit(3);
evenNumbers.forEach(System.out::println);
|
-
iterate()는 이전 요소를 seed로 해서 다음 요소를 계산한다
-
0 : 초기 seed
-
n -> n + 2 : 수행할 람다식
- 무한 스트림이라서
limit 같은 걸로 잘라야 한다
Java 9 부터 Predicate을 인자로 받아서 종료 조건을 명시할 수 있다.
1
2
|
Stream<Integer> oddNumbers = Stream.iterate(1, n -> n < 6, n -> n + 2);
oddNumbers.forEach(System.out::println); // 1 3 5
|
-
n -> n < 6 : 종료 조건
-
n -> n + 2 : 람다식
generate()
1
|
static <T> Stream<T> generate(Supplier<T> s) // 이전 요소에 독립적
|
- 인자로
Supplier<T> 람다식을 제공한다
- 이 람다식은 스트림의 각 요소를 생성할 때마다 호출되고, 매번 새로운 값을 반환하는 역할을 한다
-
Supplier는 상태가 없는 함수를 사용하는 것을 권장한다. 상태가 없는 함수는 외부 상태를 참조하지 않기 때문에, 멀티스레드 환경에서도 안전하게 사용할 수 있다.
generate()는 제공된 공급자 함수(Supplier)에 따라 값을 생성하는 스트림을 만들어준다. iterate()와 유사해 보이지만 요소의 이전 값과 상관없이 독립적으로 값을 생성한다는 점에서 다른다.
1
2
3
4
5
6
7
8
9
|
// 무작위 숫자 생성
Stream<Double> randomStream = Stream.generate(Math::random)
.limit(3);
randomStream.forEach(System.out::println);
// 동일한 값 생성
Stream<Integer> oneStream = Stream.generate(() -> 1)
.limit(4);
oneStream.forEach(System.out::println);
|
1
2
3
4
5
6
7
|
0.3747181020913669
0.3423459654756499
0.8466661074652626
1
1
1
1
|
-
generate()는 seed를 사용하지 않는다
-
generate()의 인자는 Supplier-
Supplier는 출력만 있고, 입력은 없다(주기만 한다!)
Files
파일을 소스로 하는 스트림을 만들 수 있다.
1
2
3
|
Stream<Path> Files.list(Path dir) // Path는 파일 또는 디렉토리
Stream<String> Files.lines(Path path) // 파일 내용을 라인 단위로 읽어서 문자열 스트림으로
Stream<String> Files.lines(Path path, Charset cs) // 읽을 때 사용하는 문자열 인코딩을 제공 가능
|
- 파일의 내용을 스트림 형태로 읽어들인다
- 파일을 읽는 도중
IOException이 발생할 수 있다
코드로 더 알아보자. testfile.txt이라는 텍스트 파일이 있다고 해보자.
1
2
3
4
5
|
this is line 1
this is line 2
this is line 3
this is line 4
this is line 5
|
1
2
3
4
5
6
7
8
|
String filePath = "testfile.txt"; // 파일의 경로
try (Stream<String> lines = Files.lines(Paths.get(filePath))) {
// Stream processing
lines.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
|
1
2
3
4
5
|
this is line 1
this is line 2
this is line 3
this is line 4
this is line 5
|
-
filePath: 파일 경로
-
Paths.get(filePath): filePath로 부터 Path 객체 생성
-
Files.lines(Paths.get(filePath)): 파일을 열고, 파일의 각 줄을 읽고 Stream<String>을 만들어서 반환한다
-
try 블럭 내에서 스트림에 대한 연산을 수행하면 된다
empty()
비어있는 스트림을 생성할 수 있다.
1
2
|
Stream emptyStream = Stream.empty(); // empty()는 비어있는 스트림을 반환한다
long count = emptyStream.count(); // 비어 있으니깐 count는 0
|
중간 연산(Intermediate operation)은 다음과 같다.
- 중간 연산을 수행한다
- 중간 연산은 반복적 수행이 가능하다
- 연산 결과가 스트림이다
다양한 중간 연산들에 대해 알아보자.
skip(), limit()
스트림을 자르기 위한 중간 연산.
1
2
|
Stream<T> skip(long n) // 앞에서부터 n개 건너뛰기
Stream<T> limit(long maxSize) // maxSize 이후의 요소는 잘라냄
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
String[] strArr = {"a", "b", "c", "d", "e", "f"};
ArrayList<String> arrayList = new ArrayList<>(Arrays.asList(strArr));
// 1. skip
Stream<String> strStream1 = Arrays.stream(strArr)
.skip(2);
strStream1.forEach(System.out::print); //cdef
System.out.println();
// 2. limit
Stream<String> strStream2 = Arrays.stream(strArr)
.limit(2);
strStream2.forEach(System.out::print); // ab
|
filter()
1
|
Stream<T> filter(Predicate<? super T> predicate) // 조건에 맞지 않는 요소 제거
|
-
인자:
Predicate<? super T>: 스트림의 각 요소를 테스트하는 함수형 인터페이스 Predicate를 제공한다. 요소가 조건을 만족하면 true, 그렇지 않으면 false를 반환한다.
-
반환값: 조건을 만족하는 요소만 포함된 새로운
Stream<T> 객체를 반환한다
filter()를 사용하면 스트림의 요소들 중에서 주어진 조건을 만족하는 요소만 포함된 새로운 스트림을 생성한다. 이 메서드는 주어진 조건에 맞는 요소를 선택적으로 추출하는 데 유용하다.
1
2
3
4
5
6
7
8
9
10
11
12
|
// filter
IntStream intStream2 = IntStream.rangeClosed(1, 10)
.filter(i -> i % 2 == 0); // 2와 나누어서 나머지가 0이 아니면 전부 거름(짝수 필터링)
intStream2.forEach(System.out::print); // 246810
System.out.println();
// filter를 여러번 사용하기
IntStream intStream3 = IntStream.rangeClosed(1, 100)
.filter(i -> i % 2 == 0) // 짝수 필터링
.filter(i -> i < 30) // 30미만 필터링
.filter(i -> i % 3 == 0); // 3의 배수 필터링
intStream3.forEach(System.out::print);
|
distinct()
1
|
Stream<T> distinct() // 중복 제거
|
distinct()는 스트림의 요소들 중에서 중복된 요소를 제거하여 유일한 요소만 남기도록 한다. 이 메서드는 스트림의 중복 요소를 필터링하여 결과 스트림을 생성한다.
-
distinct()는 기본적으로 스트림의 요소를 equals() 메서드를 사용하여 비교하고, 중복된 요소를 제거한다- 사용하기 위해서는 객체의
equals() 메서드가 오버라이딩 되어 있어야 한다!
-
distinct() 메서드는 원래 스트림의 순서를 유지한다
1
2
3
4
5
|
// distinct
IntStream intStream = IntStream.of(1,1,2,2,2,3,4,5,5,6,7,8,9,9)
.distinct(); // 중복 제거
intStream.forEach(System.out::print); // 123456789
System.out.println();
|
distinct()의 시간 복잡도는 O(n)이다.
sorted()
1
2
|
Stream<T> sorted() // 스트림의 요소 기본 정렬(Comparable)로 정렬
Stream<T> sorted(Comparator<? super T> comparator) // 지정된 Comparator로 정렬
|
sorted()를 사용해서 스트림을 정렬할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class SortedStream1 {
public static void main(String[] args) {
// 1. 정수 스트림 natural order로 정렬하기
Integer[] numbers = {5, 2, 8, 1, 3, 6};
Stream<Integer> sortedStream = Arrays.stream(numbers)
.sorted();
sortedStream.forEach(System.out::print); // 123568
System.out.println();
// 2. 정수 스트림 reverse order로 정렬하기
Stream<Integer> reverseStream = Arrays.stream(numbers)
.sorted((i1, i2) -> i2.compareTo(i1)); // Comparator를 제공해서 정렬 기준 제공
reverseStream.forEach(System.out::print); // 865321
System.out.println();
// 3. String 스트림 reverse order로 정렬하기
String[] words = {"apple", "banana", "cantaloupe", "dinosaur"};
Stream<String> reverseStream2 = Stream.of(words)
.sorted((s1, s2) -> s2.compareTo(s1));
reverseStream2.forEach(System.out::println); // dinosaur cantaloupe banana apple
}
}
|
특정 객체의 스트림을 정렬해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
public class SortedStream2 {
public static void main(String[] args) {
List<Person> people = List.of(
new Person("Alice", 25),
new Person("Bob", 30),
new Person("Charlie", 20),
new Person("David", 11)
);
// 1. Person 객체의 스트림을 나이를 기준으로 정렬하기
List<Person> sortedByAge = people.stream()
.sorted((p1, p2) -> Integer.compare(p1.getAge(), p2.getAge()))
.collect(Collectors.toList()); // 스트림의 요소를 컬렉트해서 리스트로 만드는 최종 연산
sortedByAge.forEach(System.out::println);
System.out.println();
// 2. Person 객체의 스트림을 이름을 기준으로 정렬하기
List<Person> sortedByName = people.stream()
.sorted((p1, p2) -> p1.getName().compareTo(p2.getName()))
.collect(Collectors.toList());
sortedByName.forEach(System.out::println);
// 3. Person 객체의 스트림을 나이를 기준으로 역으로 정렬하기
// Person::getAge = (Person p) -> p.getAge()
List<Person> revSortedByAge = people.stream()
.sorted(Comparator.comparing(Person::getAge).reversed())
.collect(Collectors.toList());
revSortedByAge.forEach(System.out::println);
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return name + " - " + age;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
David - 11
Charlie - 20
Alice - 25
Bob - 30
Alice - 25
Bob - 30
Charlie - 20
David - 11
Bob - 30
Alice - 25
Charlie - 20
David - 11
|
map()
1
|
Stream<R> map(Function<? super T, ? extends R> mapper) // Stream<T> -> Stream<R>
|
-
인자:
Function<? super T, ? extends R>: 스트림의 각 요소를 다른 타입으로 변환하는 함수형 인터페이스 Funtion이 필요하다
- 타입
T의 스트림을 타입 R의 스트림으로 변환한다
-
반환: 변환된 요소들이 포함된 새로운
Stream<R> 객체를 반환
map()은 스트림의 각 요소를 주어진 함수에 적용하여 다른 타입의 요소로 변환한 새로운 스트림을 생성한다. 이 메서드는 요소들의 변환 작업을 처리하는 데 유용하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
public class MapStream {
public static void main(String[] args) {
// 1. map() 이용해서 각 요소를 대문자로 변환
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
List<String> upperCaseNames = names.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
upperCaseNames.forEach(System.out::println);
// 2. map()을 이용해서 각 요소를 제곱한다
List<Integer> numbers = Arrays.asList(1, 2, 3);
List<Integer> squaredNumbers = numbers.stream()
.map(n -> n * n)
.collect(Collectors.toList());
squaredNumbers.forEach(System.out::println);
// 3. map()을 이용해서 String -> Integer로 변환
List<String> strings = Arrays.asList("10", "20", "30");
List<Integer> integers = strings.stream()
.map(Integer::parseInt) // Stream<String> -> Stream<Integer>
.collect(Collectors.toList());
integers.forEach(System.out::println);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
ALICE
BOB
CHARLIE
DAVID
1
4
9
10
20
30
|
flatMap()
1
|
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
|
-
Function<? super T, ? extends Stream<? extends R>>: 스트림의 각 요소를 다른 스트림으로 변환하는 함수형 인터페이스
-
T: 원본 스트림의 요소 타입
-
R: 평면화된 스트림의 요소 타입
- 각 요소에 대해
Stream<R>을 반환하고, flatMap()은 일들을 하나의 단일 스트림으로 병합한다
-
반환: 평면화된 요소들이 포함된
Stream<R> 객체를 반환
flatMap()은 스트림의 각 요소를 다수의 하위 요소들로 변환한 후, 이를 하나의 평면화된 스트림으로 만들어 반환하는 메서드이다. 즉, 여러 스트림의 차원을 축소(flatten) 시켜서 하나의 스트림으로 만든다.
map() vs flatMap()
-
map()은 각 요소를 변환하여 하나의 값을 반환
-
flatMap()은 각 요소를 변환하여 스트림이나 컬렉션 같은 다수의 값을 반환한 뒤, 이들을 모두 평평하게(flatten) 단일 스트림으로 합친다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public class FlatMapStream {
public static void main(String[] args) {
// 1. flatMap()을 사용
List<List<Integer>> nestedList = Arrays.asList( // 리스트 안의 리스트
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
// Using flatMap to flatten the nested list and filter even numbers
List<Integer> flattenedAndFiltered = nestedList.stream()
.flatMap(List::stream) // Flatten the nested list into a single stream
.filter(n -> n % 2 == 0) // Filter even numbers
.collect(Collectors.toList()); // Collect the result into a list
System.out.println("Flattened and filtered list: " + flattenedAndFiltered);
// 2. flatMap() 사용 X
List<List<Integer>> nestedList2 = Arrays.asList( // 리스트 안의 리스트
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
List<List<Integer>> filteredLists = nestedList2.stream()
.map(List::stream)
.map(innerStream -> innerStream.filter(n -> n % 2 == 0).collect(Collectors.toList()))
.collect(Collectors.toList());
System.out.println("Filtered lists: " + filteredLists);
}
}
|
1
2
|
Flattened and filtered list: [2, 4, 6, 8] // flatMap() 사용 O
Filtered lists: [[2], [4, 6], [8]] // flatMap() 사용 X
|
-
flatMap()을 사용하지 않는 경우 각 내부 스트림들이 각각 리스트로 존재하는 것을 다시 리스트로 모아지는 결과가 나옴
-
flatMap()을 사용하지 않고 flatMap()을 사용한 것과 같은 결과를 얻을 수 있는 방법들이 존재 하지만 더 복잡하다
- nested
collection을 스트림으로 처리 할 때 flatMap()을 이용해서 하나로 합치는 것이 편하다
flatMap()을 사용하는 경우
flatMap()을 사용하지 않는 경우
peek()
1
2
|
Stream<T> peek(Consumer<? super T> action) // 중간 연산 (스트림의 요소 소비 X)
void forEach(Consumer<? super T> action) // 최종 연산 (스트림의 요소 소비 O)
|
peek()는 스트림의 각 요소에 대해 특정 작업을 수행할 수 있도록 합니다. 주로 디버깅이나 로깅 목적으로 사용되며, 스트림의 요소를 변경하지 않고, 처리 과정에서 각 요소를 엿보는 데 유용하다.
스트림의 요소를 소비하지 않고 사용할 수 있다. forEach()와 유사하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class PeekStream {
public static void main(String[] args) {
// 1. peek()로 요소 출력
Stream<Integer> stream = Stream.of(1, 2, 3);
Stream<Integer> peekedStream = stream.peek(System.out::print); // peek()는 중간 연산이기 때문에 지연 연산
// 지연 연산(lazy evaluation) : 최종 연산이 수행될 때 다 같이 연산 수행
// peek()로 요소 하나 출력 -> forEach()로 요소 하나 출력 반복
peekedStream.forEach(System.out::println); // 최종 연산
// 2. peek()로 연산에 대한 로깅(logging)
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
// 필터링과 매핑 연산이 있는 스트림에 대해 peek()로 로깅
List<Integer> squaredEvenNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.peek(n -> System.out.println("Filtered: " + n)) // 필터링한 요소 로깅
.map(n -> n * n)
.peek(n -> System.out.println("Mapped: " + n)) // 매핑한 요소 로깅
.collect(Collectors.toList());
System.out.println("Squared even numbers: " + squaredEvenNumbers);
}
}
|
1
2
3
4
5
6
7
8
9
10
|
11
22
33
Filtered: 2
Mapped: 4
Filtered: 4
Mapped: 16
Filtered: 6
Mapped: 36
Squared even numbers: [4, 16, 36]
|
4. Optional
Optional<T>은 T 타입 객체의 래퍼 클래스이다.
-
non-null, null 값이 들어 있을 수 있다
- 모든 종류의 객체를 저장 가능
- 값을 감싸는 래퍼 클래스이고, NPE가 발생하지 않도록 도와준다
-
null 체크하는 코드를 포함하면 복잡해지고, null을 직접적으로 다루는 것은 위험하기 때문에 Optional을 사용하는 것을 권장
- 쉽게 말해서
null을 직접 사용하지 않고 optional에 담아서 간접적으로 이용하는 것으로 생각하면 편하다
1
2
3
4
5
|
// Optional 객체 생성
Optional<String> optVal = Optional.of(str);
Optional<String> optVal = Optional.of("this is a string");
Optional<String> optVal = Optional.of(null); // NPE 발생
Optional<String> optVal = Optional.ofNullable(null); // null을 안전하게 다루기 위해서 ofNullable() 많이 사용
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class OptionalTest {
public static void main(String[] args) {
// Create an Optional with a non-null value
Optional<String> optionalWithValue = Optional.ofNullable("Hello");
// Create an Optional with a null value
Optional<String> optionalWithNull = Optional.ofNullable(null);
// Check if the optional has a value
if (optionalWithValue.isPresent()) {
System.out.println("Value is present: " + optionalWithValue.get());
} else {
System.out.println("No value present");
}
// Check if the optional with null has a value
if (optionalWithNull.isPresent()) {
System.out.println("Value is present: " + optionalWithNull.get());
} else {
System.out.println("No value present");
}
}
}
|
1
2
|
Value is present: Hello
No value present
|
-
isPresent() : Optional 객체의 값이 null이면 false, 아니면 true 반환
1
2
3
4
5
6
|
// 1. Optional 객체 초기화
Optional<String> optVal = Optional.empty();
// 2. Optional 객체의 값 가져오기
String str1 = optVal.orElse(""); // optVal에 저장된 값이 null이면, ""를 반환
String str2 = optVal.orElseGet(String::new); // 람다식 사용가능, () -> new String()
|
5. 최종 연산(Terminal Operation)
최종 연산에 대해서 알아보자. 들어가기에 앞서 최종 연산의 특징을 다시 살펴보자.
-
최종 연산(Terminal operation)
- 최종 연산을 수행한다
- 최종 연산은 단 1번만 수행한다
- 최종 연산을 통해서 결과가 만들어진다
- 결과는 스트림이 아니다(스트림의 요소를 소모)
forEach()
스트림의 모든 요소에 지정된 작업을 수행한다.
1
2
|
void forEach(Consumer<? super T> action) // 병렬 스트림인 경우 순서가 보장되지 않는다
void forEachOrdered(Consumer<? super T> action) // 병렬 스트림인 경우에도 순서가 보장됨
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class ForEachTest {
public static void main(String[] args) {
// 1. 맵의 각 요소를 forEach()를 이용해서 출력
Map<Integer, String> studentMap = new HashMap<>();
studentMap.put(1, "Alice");
studentMap.put(2, "Bob");
studentMap.put(3, "Charlie");
studentMap.forEach((key, value) -> System.out.println("Key: " + key + ", Value: " + value));
// 2. forEach()를 이용해서 리스트의 각 요소를 대문자로 변환
List<String> fruits = Arrays.asList("Apple", "Banana", "Orange", "Mango");
// 각 요소를 대문자로 변환
fruits.forEach(fruit -> {
String upperCaseFruit = fruit.toUpperCase();
// 대문자로 변환된 요소를 출력하는 작업까지 포함
System.out.println("Processed fruit: " + upperCaseFruit);
});
}
}
|
1
2
3
4
5
6
7
8
|
Key: 1, Value: Alice
Key: 2, Value: Bob
Key: 3, Value: Charlie
Processed fruit: APPLE
Processed fruit: BANANA
Processed fruit: ORANGE
Processed fruit: MANGO
|
-
forEach()의 사용은 Stream에만 국한되는 것이 아님
-
Iterable 인터페이스를 구현하는 객체면 forEach() 사용 가능
xxxMatch()
요소의 조건 검사를 위한 최종 연산.
1
2
3
|
boolean allMatch(Predicate<? super T> predicate) // 모든 요소가 조건을 만족시키면 true
boolean anyMatch(Predicate<? super T> predicate) // 한 요소라도 조건을 만족시키면 true
boolean noneMatch(Predicate<? super T> predicate) // 모든 요소가 조건을 만족시키지 않으면 true
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class MatchTest {
public static void main(String[] args) {
// 1. allMatch() - 모든 요소가 조건을 만족하면 true
List<Integer> numbers = Arrays.asList(2, 4, 6, 8, 10);
// Check if all numbers are even
boolean allEven = numbers.stream().allMatch(n -> n % 2 == 0);
System.out.println("All numbers are even: " + allEven);
// 2. anyMatch() - 한 요소라도 조건을 만족하면 true
// Check if at least one fruit starts with "B"
boolean anyStartsWithB = Stream.of("Apple", "Banana", "Orange", "Mango").
anyMatch(fruit -> fruit.startsWith("B"));
System.out.println("At least one fruit starts with 'B': " + anyStartsWithB);
// 3. noneMatch() - 모든 요소가 조건을 만족시키지 않으면 true
List<Integer> oddNumbers = Arrays.asList(3, 5, 7, 9, 11);
// Check if no number is even
boolean noneEven = oddNumbers.stream().noneMatch(n -> n % 2 == 0);
System.out.println("No number is even: " + noneEven);
}
}
|
1
2
3
|
All numbers are even: true
At least one fruit starts with 'B': true
No number is even: true
|
findxxx()
조건에 일치하는 요소를 찾는다.
1
2
|
Optional<T> findFirst() // 첫 번째 요소를 반환한다, 순차 스트림(sequential)에 사용
Optional<T> findAny() // 아무 요소 하나를 반환, 병렬 스트림(parallel)에 사용
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class FindTest {
public static void main(String[] args) {
// 1. findFirst() - 첫 번째 요소를 반환
Optional<String> first = Stream.of("apple", "banana", "cherry", "date")
.findFirst();
first.ifPresent(System.out::println); // 스트림에 findFirst() 연산을 통해 값이 존재하면 출력
// 2. findAny() - 아무 요소 하나를 반환, (순차 스트림)
Stream<String> stream = Stream.of("apple", "banana", "cherry", "date", "eclipse");
Optional<String> any = stream.findAny();
any.ifPresent(System.out::println); // 현재 스트림은 순차(sequential)이기 때문에 똑같이 apple 출력
// 2. findAny() - (병렬 스트림)
Optional<String> any2 = Stream.of("apple", "banana", "cherry", "date", "eclipse")
.parallel()
.findAny();
any2.ifPresent(System.out::println); // apple, banana, cherry.. 아무 값이 올 수 있음
}
}
|
-
ifPresent() : Optional 객체가 값을 가지고 있으면 인자로 가지고 있는 Consumer 실행
reduce()
스트림의 요소를 하나씩 줄여가면 누적연산을 수행한다.
1
2
3
|
Optional<T> reduce(BinaryOperator<T> accumulator) // identity 생략, 스트림이 null이 될 수 있기 때문에 Optional 사용
T reduce(T identity, BinaryOperator<T> accumulator)
U reduce(U identity, BiFunction<U, T, U> accumulator, BinaryOperator<T> combiner)
|
-
identity: 초기값
-
accumulator: 이전 연산결과와 스트림의 요소에 수행할 연산
-
combiner: 병렬 처리된 결과를 합치는데 사용할 연산 (병렬 스트림)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
public class ReduceTest {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 1. reduce(BinaryOperator<T> accumulator)
// Sum all elements of the stream
int sum = numbers.stream()
.reduce((a, b) -> a + b)
.orElse(0);
System.out.println("Sum of all elements = " + sum);
// 2. reduce(T identity, BinaryOperator<T> accumulator)
// Sum all elements of the stream with an initial value of 10
int sum2 = numbers.stream()
.reduce(10, (a, b) -> a + b);
System.out.println("Sum of all elements with initial value 10 = " + sum2);
// 3. reduce(T identity, BinaryOperator<T> accumulator) -
Integer[] numbers2 = {1, 2, 3, 4, 5};
// Calculate the product of all numbers using reduce
// 모든 요소의 곱
int product = Arrays.stream(numbers2)
.reduce(1, (a, b) -> a * b); // 누적 연산 결과 : a, 스트림의 요소 : b
System.out.println("Product of numbers = " + product); // 결과 : 120
// 4. reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
// Parallel sum of all elements of the stream
int sum3 = numbers.parallelStream()
.reduce(0, (a, b) -> a + b, Integer::sum);
System.out.println("Parallel sum of all elements: " + sum3);
}
}
|
1
2
3
4
|
Sum of all elements = 15
Sum of all elements with initial value 10 = 25
Product of numbers = 120
Parallel sum of all elements: 15
|
collect()
collect()는 Collector를 매개변수로 하는 스트림의 최종연산.
1
2
|
Object collect(Collector collector) // Collector를 구현한 클래스의 객체를 매개변수로
Object collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner) // 잘 사용하지는 않음
|
-
Collector는 collect()에 필요한 메서드를 정의해 놓은 인터페이스.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
public class CollectTest {
public static void main(String[] args) {
// 1. toList()
List<String> words = Arrays.asList("apple", "banana", "cherry");
List<String> resultList = words.stream()
.collect(Collectors.toList());
System.out.println("Result List: " + resultList); // Output: Result List: [apple, banana, cherry]
// 2. toSet()
Set<String> words2 = Arrays.asList("apple", "banana", "cherry", "banana").stream()
.collect(Collectors.toSet());
System.out.println("Result Set: " + words2); // Output: Result Set: [apple, banana, cherry]
// 3. toMap()
Map<String, Integer> wordLengthMap = Arrays.asList("apple", "banana", "cherry")
.stream()
.collect(Collectors.toMap(
word -> word, // Key mapper
String::length)); // Value mapper
System.out.println("Word Length Map: " + wordLengthMap); // Output: Word Length Map: {apple=5, banana=6, cherry=6}
// 4. joining()
// List of strings
List<String> words3 = Arrays.asList("Hello", "World", "Java");
// Collect the strings into a single comma-separated string
String result = words3.stream()
.collect(Collectors.joining(", "));
System.out.println("Result: " + result); // Output: Result: Hello, World, Java
// 5. summarizingInt()
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
IntSummaryStatistics stats = numbers.stream()
.collect(Collectors.summarizingInt(Integer::intValue));
// Output: Statistics: IntSummaryStatistics{count=5, sum=15, min=1, average=3.000000, max=5}
System.out.println("Statistics: " + stats);
}
}
|
1
2
3
4
5
|
Result List: [apple, banana, cherry]
Result Set: [banana, apple, cherry]
Word Length Map: {banana=6, apple=5, cherry=6}
Result: Hello, World, Java
Statistics: IntSummaryStatistics{count=5, sum=15, min=1, average=3.000000, max=5}
|
-
Collectors는 다양한 기능의 메서드 지원
- 변환 :
mapping(), toList(), toSet(), toMap(), toCollection()
- 통계 :
counting(), summingInt(), maxBy(), summarizingInt()
- 문자열 결합 :
joining()
- 리듀싱 :
reducing() - 그룹별 리듀싱 가능
- 그룹화와 분할 :
groupingBy(), partitioningBy(), collectingAndThen()
partitioningBy(), groupingBy()
1
2
|
partitioningBy(Predicate<? super T> predicate) // 스트림을 2분할
groupingBy(Function<? super T, ? extends K> classifier) // 스트림을 n분할
|
-
partitioningBy(): 주어진 조건(불리언 조건)에 따라 스트림을 두 그룹으로 나눈다- 반환값은
Map<Boolean, List<T>>: true 조건에 해당하는 요소들이 하나의 리스트에, false 조건에 해당하는 요소들이 다른 리스트에 들어간다
-
groupingBy(): 주어진 기준에 따라 스트림을 여러 그룹으로 나눌 수 있다- 반환 값은
Map<K, List<T>>: K는 그룹핑하는 기준이며, T는 그룹에 속하는 요소의 타입이다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class CollectTest2 {
public static void main(String[] args) {
// 1. partitioningBy() - 스트림을 2분할
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 2의 배수면 true, 2의 배수가 아니면 false로 분할
Map<Boolean, List<Integer>> partitions = numbers.stream()
.collect(Collectors.partitioningBy(n -> n % 2 == 0));
System.out.println("Partitions: " + partitions); // Partitions: {false=[1, 3, 5], true=[2, 4]}
// 2. groupingBy() - 스트림을 n분할
List<String> words = Arrays.asList("apple", "banana", "cherry", "cantaloupe");
// 각 문자열의 길이 별로 그룹핑
Map<Integer, List<String>> groups = words.stream()
.collect(Collectors.groupingBy(String::length));
System.out.println("Groups: " + groups); // Groups: {5=[apple], 6=[banana, cherry], 10=[cantaloupe]}
}
}
|
1
2
|
Partitions: {false=[1, 3, 5], true=[2, 4]}
Groups: {5=[apple], 6=[banana, cherry], 10=[cantaloupe]}
|
Reference
- https://innovationm.co/concept-of-stream-api-java1-8/
- https://mangkyu.tistory.com/114
- 이것이 자바다!
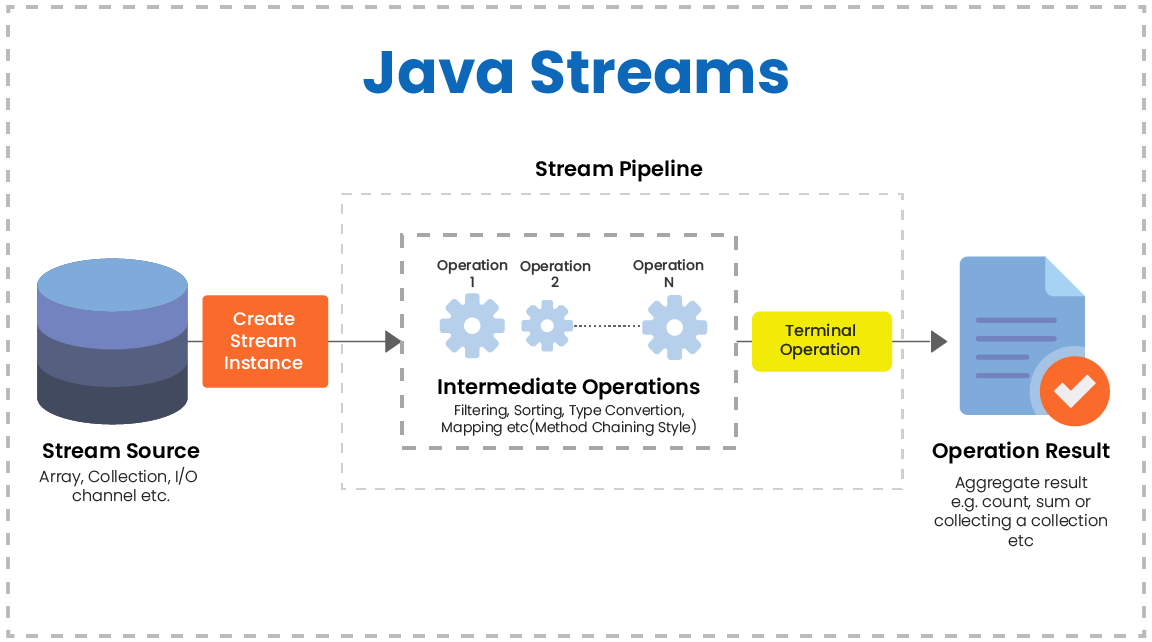 https://innovationm.co/concept-of-stream-api-java1-8/
https://innovationm.co/concept-of-stream-api-java1-8/ 스트림의 연산 과정
스트림의 연산 과정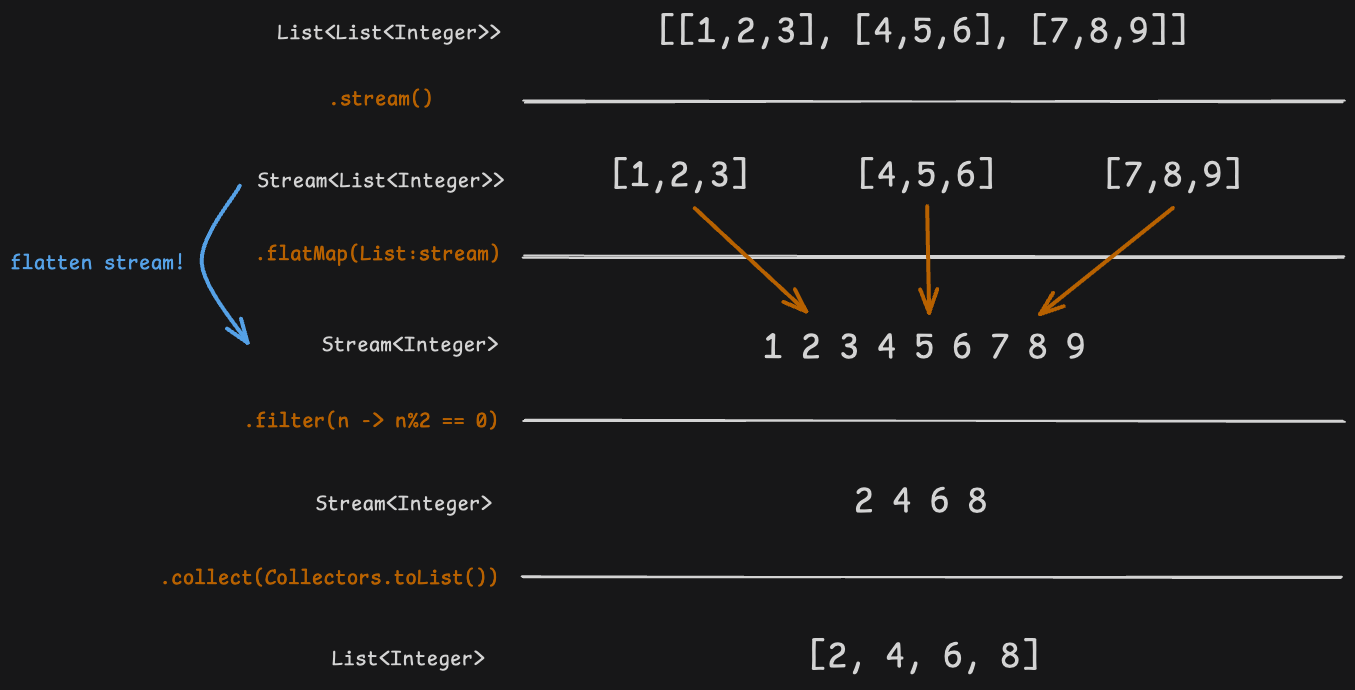 flatMap()을 사용하는 경우
flatMap()을 사용하는 경우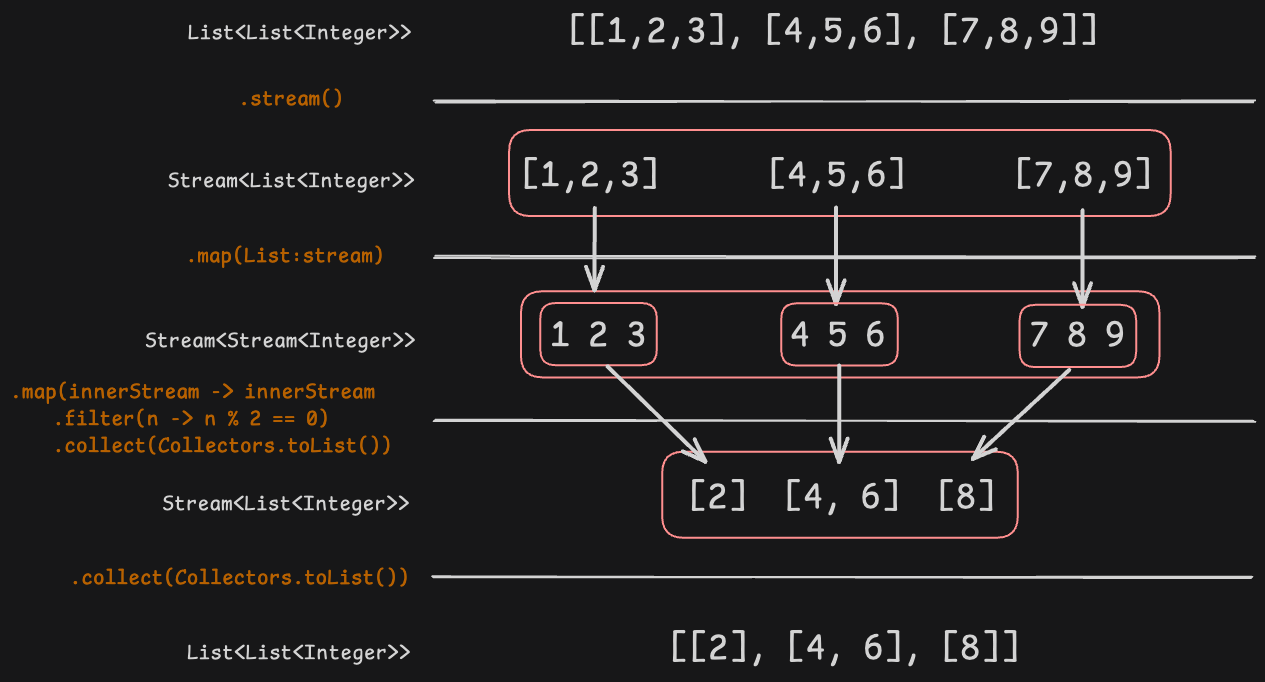 flatMap()을 사용하지 않는 경우
flatMap()을 사용하지 않는 경우
Comments powered by Disqus.