(Java - 30) Executor 프레임워크
자바의 Executor 프레임워크 소개, 사용법
2024-07-18 업데이트
해당 포스트는 Lombok과
@Slf4j(Logback)를 사용한다로그는
logstash-logback-encoder를 통해 JSON 형태로 파싱하고 있다. 편의상version,level,levelValue필드를 제외하고 사용했다.만약 로깅에 익숙하지 않다면 로깅 대신
System.out을 사용하면 된다.
1. Executor
직접 스레드를 생성하는 것은 비효율적이다
스레드를 직접 생성해서 사용하는 경우 다음의 문제점이 있다.
-
스레드 생성 비용은 비싸다
- 스레드를 사용하기 위해서는 스레드를 생성해야 한다. 그러나 스레드의 생성 비용은 생각보다 비싸다.
- 스레드는 자신만의 호출 스택(call stack)을 가지고 있어야 한다. 그러기 위해서 호출 스택을 위한 메모리를 할당해줘야 한다.
- 실제 스레드의 생성 자체는 커널 레벨(kernel level)에서 이루어지며, 이는 CPU와 메모리 자원을 소모한다.
- 새롭게 생성된 스레드는 운영체제의 스케쥴러를 통해서 관리되고, 이를 스케쥴 알고리즘에 포함하기 위한 오버헤드가 발생할 수 있다.
- 아주 가벼운 작업이라면, 스레드의 생성 시간이 작업의 실행 시간보다 긴 상황이 발생할 수 있다
- 스레드를 사용하기 위해서는 스레드를 생성해야 한다. 그러나 스레드의 생성 비용은 생각보다 비싸다.
-
스레드를 관리하는 것은 어렵다
- 스레드 수 관리의 어려움: 직접 스레드를 생성할 때, 몇 개의 스레드를 생성해야 할지, 언제 스레드를 생성하거나 종료할지를 결정하는 것이 어렵다. 너무 많은 스레드를 생성하면 오버헤드가 발생하고, 너무 적게 생성하면 병렬 처리가 제대로 이루어지지 않아 성능이 떨어질 수 있다. 최적의 스레드 수를 관리하는 것은 어려운 과제이다.
-
자원 관리의 어려움: 무제한으로 스레드를 생성하게 되면, 시스템의 스레드 자원 한계를 초과할 수 있다. 이는 메모리 부족(
OutOfMemoryError), 등의 심각한 문제를 초래할 수 있다. - 스레드 생명 주기 관리의 복잡성: 스레드를 생성한 후에는 그 스레드의 생명 주기를 관리해야 한다. 즉, 스레드가 언제 종료되어야 할지를 결정하고, 불필요한 스레드가 계속 실행되지 않도록 해야 한다. 스레드의 생명 주기를 잘못 관리하면, 종료되지 않은 스레드가 리소스를 계속 점유하여 리소스 누수가 발생할 수 있다.
-
Runnable인터페이스는 불편하다-
결과 반환의 어려움:
Runnable인터페이스는 작업을 수행할 수 있는run()메서드를 정의하지만, 결과를 반환할 수 있는 방법을 제공하지 않는다. 작업이 완료된 후 결과를 받아야 하는 경우,Runnable은 직접적인 방법을 제공하지 않으므로, 추가적인 로직이 필요하다. -
예외 처리의 어려움:
Runnable의run()메서드는 예외를 던질 수 없다. 만약 작업 도중 예외가 발생하면, 이를try-catch블록으로 처리해야 한다. 이로 인해 코드가 복잡해질 수 있으며, 일관된 예외 처리가 어렵다. -
자원 관리와 동기화의 어려움:
Runnable은 스레드의 생성과 실행만을 담당하고, 자원 관리와 동기화는 사용자가 직접 처리해야 한다.
-
결과 반환의 어려움:
스레드 풀(ThreadPool)
스레드 생성 비용이 비싼 문제와 스레드의 관리를 용이하게 하기 위해서 스레드 풀(Thread Pool)이라는 개념을 사용한다.
스레드 풀(Thread Pool)은 다수의 스레드를 미리 생성하여 재사용하는 패턴으로, 스레드 생성과 관리의 오버헤드를 줄이고, 자원 사용을 최적화하는 데 도움을 준다. 스레드 풀을 사용하면 스레드를 반복적으로 생성하고 종료하는 대신, 필요할 때 이미 생성된 스레드를 재사용할 수 있다. 이를 통해 애플리케이션의 성능과 응답성을 향상시킬 수 있다.
 Thread Pool
Thread Pool
- 스레드 미리 생성: 스레드 풀은 일정 수의 스레드를 미리 생성하고, 작업이 들어올 때마다 이러한 스레드 중 하나를 할당하여 작업을 실행한다.
-
작업 큐: 작업을 스레드 풀에 제출하면, 스레드 풀은 작업을 작업 큐(task queue)에 저장하거나, 즉시 사용할 수 있는 스레드에 할당하여 실행한다. 스레드가 작업을 완료하면, 작업 큐에서 새로운 작업을 가져와서 처리한다.
- 보통
BlockingQueue로 구현된다
- 보통
- 스레드 재사용: 스레드 풀에서 사용된 스레드는 작업이 끝난 후 종료되지 않고 다시 풀로 돌아간다. 이로 인해 스레드를 반복적으로 생성하거나 종료하는 오버헤드를 줄일 수 있다.
-
스레드 수 관리: 스레드 풀은 기본적으로 두 가지 중요한 스레드 수를 관리한다
- Core Pool Size (기본 스레드 수): 스레드 풀이 항상 유지하고자 하는 최소 스레드 수
- Maximum Pool Size (최대 스레드 수): 스레드 풀이 동시에 유지할 수 있는 최대 스레드 수
Executor 프레임워크 소개
Executor 프레임워크는 Java에서 제공하는 고수준의 동시성 프로그래밍을 위한 프레임워크로, 스레드를 직접 생성하고 관리하는 번거로움을 줄이고, 효율적으로 스레드를 사용할 수 있도록 도와준다. 이 프레임워크는 자바 5에서 처음 도입되었으며, 주요 구성 요소로는 Executor, ExecutorService, ScheduledExecutorService, ThreadPoolExecutor 등이 있다.
Executor 프레임워크는 스레드 생성과 관리를 추상화하여 동시성 프로그래밍을 더 간단하고 안전하게 만들어 준다. Executor 프레임워크는 스레드 풀을 활용하면서 자원 관리, 예외 처리, 코드 유지보수성, 그리고 확장성 측면에서 많은 이점을 제공하며, 멀티코어 시스템에서의 효율적인 성능 발휘에 기여한다. 이러한 이유들로 인해, Java 애플리케이션에서 복잡한 멀티스레딩 작업을 수행할 때 Executor 프레임워크를 사용하는 것이 권장된다.
쉽게 말해서 작업 실행의 관리 및 스레드 풀 관리를 효율적으로 처리해서 개발자가 직접 스레드를 생성하고 관리하는 복잡함을 줄여준다.
Executor 인터페이스: Executor는 Executor 프레임워크의 가장 기본적인 인터페이스로, 단순히 작업을 실행하는 방법을 정의한다
1
2
3
4
5
6
7
8
9
10
11
12
13
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
- 이 인터페이스는 작업 실행에 대한 개념적 추상화를 제공한다
- 쉽게 말해서, 작업 실행에 대한 간단한 인터페이스로, 스레드 관리의 세부 사항을 숨긴다
ExecutorService 인터페이스: ExecutorService는 Executor를 확장한 인터페이스로, 다양한 기능을 제공한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public interface ExecutorService extends Executor, AutoCloseable {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
@Override
default void close() {
//...
}
}
-
Future<?> submit(Runnable task): 비동기적으로Runnable작업을 실행하고,Future객체를 반환하여 작업의 완료 상태를 추적할 수 있게 한다 -
<T> Future<T> submit(Callable<T> task):Callable작업을 비동기적으로 실행하고, 작업의 결과를 반환할 수 있는Future<T>객체를 반환한다 -
void shutdown(): 새로운 작업 제출을 중단하고, 기존 작업이 완료될 때까지 기다린다 - 이외에도 다양한 메서드를 지원한다
-
Executor프레임워크는 대부분ExecutorService인터페이스를 통해서 사용한다
ThreadPoolExecutor 클래스는 ExecutorService 인터페이스의 가장 기본적인 구현체이다. 이 클래스는 다양한 설정 옵션을 제공하여 스레드 풀의 크기, 작업 큐의 종류, 작업 처리 방식 등을 세밀하게 제어할 수 있다.
2. Executor 프레임워크 사용하기
ExecutorService 예시
ExecutorService를 사용하는 아주 간단한 예시를 살펴보자.
먼저 ExecutorService의 상태를 출력하는 유틸을 만들자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Slf4j
public class ExecutorUtils {
public static void printState(ExecutorService executorService) {
if (executorService instanceof ThreadPoolExecutor poolExecutor) { // ThreadPoolExecutor 구현체가 넘어오는 경우
int pool = poolExecutor.getPoolSize(); // 스레드 풀에서 관리되는 스레드의 숫자
int active = poolExecutor.getActiveCount(); // 작업을 수행하는 스레드의 숫자
int queuedTasks = poolExecutor.getQueue().size(); // 큐에 대기중인 작업의 숫자
long completedTask = poolExecutor.getCompletedTaskCount(); // 완료된 작업의 숫자
log.info("[pool = {}, active = {}, queuedTasks = {}, completedTasks = {}", pool, active, queuedTasks, completedTask);
} else {
// ThreadPoolExecutor 구현체가 아닌 경우 인스턴스 자체 출력
log.info("executorService = {}", executorService);
}
}
}
기본적으로 1000ms 대기하고, 시간을 지정해서 대기 할 수 있는 작업을 만들자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Slf4j
public class RunnableTask implements Runnable {
private final String name;
private int sleepTime = 1000;
public RunnableTask(String name) {
this.name = name;
}
public RunnableTask(String name, int sleepTime) {
this.name = name;
this.sleepTime = sleepTime;
}
@Override
public void run() {
log.info("{} 시작", name);
ThreadUtils.sleep(sleepTime);
log.info("{} 완료", name);
}
}
실행 코드를 만들고, 실행해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
@Slf4j
public class ExecutorBasicExMain {
public static void main(String[] args) {
ExecutorService es = new ThreadPoolExecutor(
2,
2,
0,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>());
log.info("----초기 상태----");
ExecutorUtils.printState(es);
es.execute(new RunnableTask("task-A"));
es.execute(new RunnableTask("task-B"));
es.execute(new RunnableTask("task-C"));
es.execute(new RunnableTask("task-D"));
log.info("----작업 수행 중----");
ExecutorUtils.printState(es);
ThreadUtils.sleep(3000);
log.info("----작업 수행 완료----");
ExecutorUtils.printState(es);
// 현재 자바 >= 자바19 : close() 사용
// < 자바19 : shutdown() 사용
es.close();
log.info("---- shutdown ----");
ExecutorUtils.printState(es);
}
}
-
ExecutorService es = new ThreadPoolExecutor(2, 2, 0, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>())ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, timeUnit, taskQueue0)-
corePoolSize: 스레드 풀에서 관리되는 기본 스레드 수 -
maximumPoolSize: 스레드 풀에서 관리되는 최대 스레드 수 -
keepAliveTime: 기본 스레드 수를 초과해서 만들어진 스레드가 생존할 수 있는 대기 시간. 해당 시간 동안 작업이 없으면 초과 스레드는 제거된다. -
taskQueue: 작업을 보관할BlockingQueue- 현재의 예시는
LinkedBlockingQueue<>()를 사용한다. 이 블로킹 큐는 작업을 무한대로 저장할 수 있다
- 현재의 예시는
-
es.execute(new RunnableTask("task-A"))-
RunnableTask("task-A")의 인스턴스가 작업 큐(BlockingQueue)에 보관된다
-
실행 결과.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{"@timestamp":"2024-07-19T23:17:29.746282+09:00","message":"----초기 상태----","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:29.749917+09:00","message":"[pool = 0, active = 0, queuedTasks = 0, completedTasks = 0","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:29.751051+09:00","message":"task-B 시작","thread_name":"pool-1-thread-2"}
{"@timestamp":"2024-07-19T23:17:29.751479+09:00","message":"----작업 수행 중----","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:29.751015+09:00","message":"task-A 시작","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-19T23:17:29.751716+09:00","message":"[pool = 2, active = 2, queuedTasks = 2, completedTasks = 0","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:30.756997+09:00","message":"task-B 완료","thread_name":"pool-1-thread-2"}
{"@timestamp":"2024-07-19T23:17:30.757393+09:00","message":"task-A 완료","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-19T23:17:30.758187+09:00","message":"task-C 시작","thread_name":"pool-1-thread-2"}
{"@timestamp":"2024-07-19T23:17:30.758207+09:00","message":"task-D 시작","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-19T23:17:31.75885+09:00","message":"task-D 완료","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-19T23:17:31.761998+09:00","message":"task-C 완료","thread_name":"pool-1-thread-2"}
{"@timestamp":"2024-07-19T23:17:32.756942+09:00","message":"----작업 수행 완료----","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:32.758092+09:00","message":"[pool = 2, active = 0, queuedTasks = 0, completedTasks = 4","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:32.760263+09:00","message":"---- shutdown ----","thread_name":"main"}
{"@timestamp":"2024-07-19T23:17:32.760526+09:00","message":"[pool = 0, active = 0, queuedTasks = 0, completedTasks = 4","thread_name":"main"}
동작을 그림으로 살펴보면 다음과 같다.
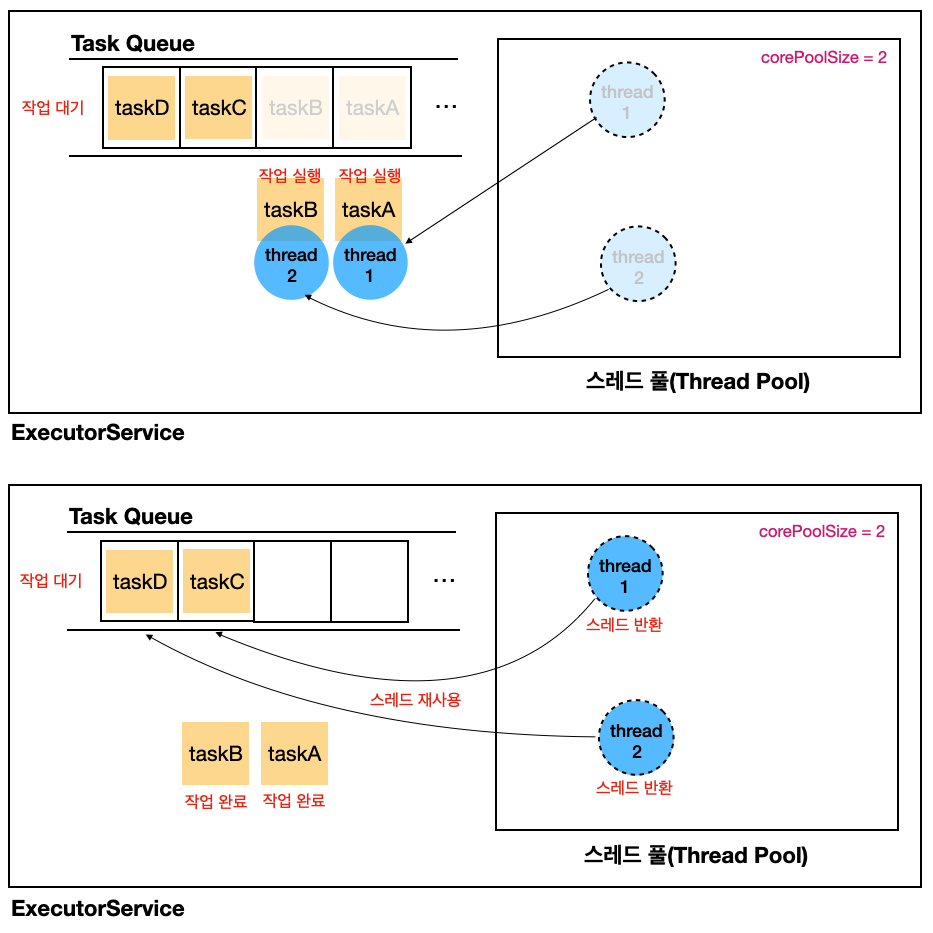 ExecutorService
ExecutorService
Runnable의 불편함
이전에 Runnable 인터페이스가 불편한 이유를 다음과 같이 설명했다.
-
결과 반환의 어려움
-
Runnable인터페이스는 작업을 수행할 수 있는run()메서드를 정의하지만, 결과를 반환할 수 있는 방법을 제공하지 않는다. - 작업이 완료된 후 결과를 받아야 하는 경우,
Runnable은 직접적인 방법을 제공하지 않으므로, 추가적인 로직이 필요하다.
-
-
예외 처리의 어려움
-
Runnable의run()메서드는 예외를 던질 수 없다. - 작업 도중 예외가 발생하면, 이를
try-catch블록으로 처리해야 한다. 이로 인해 코드가 복잡해질 수 있으며, 일관된 예외 처리가 어렵다.
-
-
자원 관리와 동기화의 어려움
-
Runnable은 스레드의 생성과 실행만을 담당하고, 자원 관리와 동기화는 사용자가 직접 처리해야 한다.
-
코드를 통해 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
@Slf4j
public class RunnableMain {
private static int result; // 계산 결과를 저장하는 외부 변수
public static void main(String[] args) throws InterruptedException {
Runnable task = new Runnable() {
@Override
public void run() {
log.info("---Runnable 시작---");
int a = 10;
int b = 20;
result = a + b; // 결과를 외부 변수에 저장
log.info("task.result = {}", result);
log.info("---Runnable 완료---");
}
};
Thread thread = new Thread(task, "Thread-0");
thread.start();
thread.join(); // 스레드가 끝날 때까지 기다림
// 결과 출력
log.info("result = {}", result);
}
}
1
2
3
4
{"@timestamp":"2024-07-20T14:07:48.85537+09:00","message":"---Runnable 시작---","thread_name":"Thread-0"}
{"@timestamp":"2024-07-20T14:07:48.858774+09:00","message":"task.result = 30","thread_name":"Thread-0"}
{"@timestamp":"2024-07-20T14:07:48.859269+09:00","message":"---Runnable 완료---","thread_name":"Thread-0"}
{"@timestamp":"2024-07-20T14:07:48.859379+09:00","message":"result = 30","thread_name":"main"}
-
Runnable로 정의한 작업은a+b를result라는 외부 변수에 저장하는 작업 -
main스레드에서 이 값을 얻어오기 위해서는Thread-0스레드가 끝날 때 까지join()으로 대기하고 있어야 한다 - 이후에
result를 통해 값에 접근해서 사용할 수 있다
여기서 Runnable을 사용해서 불편한 점은 다음과 같다.
-
외부 변수 필요
- 외부 변수
result에 값을 보관하고 있다가 꺼내서 사용한다 -
result를 작업 안에서 정의해도 상황은 똑같다.main에서task.result같은 형태로 꺼내서 사용해야 한다.
- 외부 변수
-
join() 필요
- 값을 저장했다가,
Thread-0가 끝날 때 까지main스레드를join()으로 대기시키고, 이후에 보관된 값을 다시 꺼내는 일련의 과정이 너무 복잡하다
- 값을 저장했다가,
-
동기화 필요
- 위에서 다루진 않았지만, 여러 스레드가 동시에 결과를 읽고 기록한다면, 해당 멀티 스레드에 대한 동기화 과정도 필요하다
만약 작업 스레드에서 return을 통해 결과값을 반환하고, 해당 반환값을 바로 받을 수 있다면 훨씬 간편할 것이다.
지금부터 알아볼 Callable과 Future라는 인터페이스는 이를 가능하게 한다.
3. Future, Callable 인터페이스
Callable 소개
Callable은 Runnable과 유사한 인터페이스로, 비동기 작업을 정의하는 데 사용된다. 하지만 Runnable과는 달리 Callable은 작업이 완료된 후 결과를 반환할 수 있으며, 작업 도중 예외를 던질 수 있다.
1
2
3
public interface Callable<V> {
V call() throws Exception;
}
-
call()의 반환 타입은V: 값 반환이 가능하다 -
throws Exception:Exception그 하위 예외를 모두 던지는 것이 가능하다
예시는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
// 작업 수행
int sum = 0;
for (int i = 1; i <= 10; i++) {
sum += i;
}
return sum; // 결과 반환이 가능하다
}
}
Future 소개
Future는 비동기 작업의 결과를 나타내는 인터페이스이다. Future는 Callable 또는 Runnable이 제출된 후 작업의 상태를 조회하고, 작업이 완료된 후 결과를 가져오며, 작업이 완료될 때까지 기다릴 수 있는 메서드를 제공한다.
Future 인터페이스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
public interface Future<V> {
/**
* Attempts to cancel execution of this task. This method has no
* effect if the task is already completed or cancelled, or could
* not be cancelled for some other reason. Otherwise, if this
* task has not started when {@code cancel} is called, this task
* should never run. If the task has already started, then the
* {@code mayInterruptIfRunning} parameter determines whether the
* thread executing this task (when known by the implementation)
* is interrupted in an attempt to stop the task.
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
* Returns {@code true} if this task was cancelled before it completed
* normally.
*/
boolean isCancelled();
/**
* Returns {@code true} if this task completed.
*/
boolean isDone();
/**
* Waits if necessary for the computation to complete, and then
* retrieves its result.
*/
V get() throws InterruptedException, ExecutionException;
/**
* Waits if necessary for at most the given time for the computation
* to complete, and then retrieves its result, if available.
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
/**
* Returns the computed result, without waiting.
* @since 19
*/
default V resultNow() {
//...
}
/**
* Returns the exception thrown by the task, without waiting.
* @since 19
*/
default Throwable exceptionNow() {
//...
}
/**
* Represents the computation state.
* @since 19
*/
enum State {
RUNNING,
SUCCESS,
FAILED,
CANCELLED
}
/**
* {@return the computation state}
* @since 19
*/
default State state() {
//...
}
}
-
boolean cancel(boolean mayInterruptIfRunning)- 이미 실행 중인 작업을 취소할 수 있는 메서드
-
mayInterruptIfRunning이true로 설정된 경우, 실행 중인 스레드가 중단될 수 있다 - 작업이 이미 완료되었거나, 이미 취소되었거나, 또는 다른 이유로 취소할 수 없는 상태라면
false를 반환한다 - 성공적으로 취소되면
true를 반환한다
-
boolean isCancelled()- 작업이 성공적으로 취소되었는지 여부를 확인한다
-
cancel()메서드가 성공적으로 호출되어 작업이 취소된 경우true를 반환한다
-
boolean isDone()- 작업이 완료되었는지 확인하는 메서드
- 작업이 정상적으로 완료되었거나, 예외로 인해 종료되었거나, 취소되었을 경우
true를 반환한다
-
V get()- 작업이 완료될 때까지 기다렸다가 결과를 반환하는 메서드
- 작업이 완료되기 전까지 현재 스레드를 차단(block)한다
- 작업이 완료되면 결과를 반환한다
- 작업이 예외를 발생시키며 종료된 경우
ExecutionException이 발생한다 - 작업이 취소된 경우
CancellationException이 발생한다 - 인터럽트가 발생할 경우
InterruptedException이 발생할 수 있다
-
V get(long timeout, TimeUnit unit)-
get()메서드와 유사하지만, 주어진 시간 동안만 대기하는 메서드 - 지정된 시간 내에 작업이 완료되지 않으면
TimeoutException을 발생시킨다
-
Future 예시 1
Future와 Callable을 사용하는 간단한 예시를 살펴보자. 이전에 Runnable을 통해서 구현한 a+b의 결과를 얻어오는 것을 구현해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Slf4j
public class CallableEx1Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(1); // 스레드 풀 사이즈 1의 간단한 ExecutorService 생성
Future<Integer> future = es.submit(new MyCallable());
Integer result = future.get();
log.info("future.get() = {}", result);
es.close();
}
private static class MyCallable implements Callable<Integer> { // 반환 타입 Integer
@Override
public Integer call() {
log.info("---Callable 시작---");
ThreadUtils.sleep(2000);
int a = 10;
int b = 20;
int result = a + b;
log.info("Callable result = {}", result);
log.info("---Callable 종료---");
return result; // Runnable과 달리 결과를 반환할 수 있다
}
}
}
1
2
3
4
{"@timestamp":"2024-07-20T14:51:07.346122+09:00","message":"---Callable 시작---","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-20T14:51:09.354881+09:00","message":"Callable result = 30","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-20T14:51:09.359162+09:00","message":"---Callable 종료---","thread_name":"pool-1-thread-1"}
{"@timestamp":"2024-07-20T14:51:09.363006+09:00","message":"future.get() = 30","thread_name":"main"}
-
MyCallable implements Callable<Integer>: 제네릭 타입을<Integer>로 선언했다(숫자 반환)-
Runnable과 달리 결과를 반환할 수 있다
-
-
ExecutorService es = Executors.newFixedThreadPool(1): 스레드 풀 사이즈 1의 간단한ExecutorService생성 -
Future<Integer> future = es.submit(new MyCallable()):ExecutorService의submit()을 통해서Callable을 전달한다-
new MyCallable()을 통해 생성된 인스턴스가 작업 큐에 전달되고, 스레드 풀의 스레드 하나를 받아서 해당 작업을 실행한다 - 작업 처리의 결과는
Future라는 인터페이스를 통해서 반환된다
-
-
Integer result = future.get():.get()을 통해서 해당 작업의call()이 반환한 결과를 받을 수 있다-
Runnable과 달리 따로 결과를 보관할 필드는 만들지 않아도 된다
-
위 코드의 특징을 한번 정리해보자.
-
Callable을 사용하면Runnable과 달리 결과를 반환할 수 있다-
Runnable과 달리 따로 결과를 보관할 필드는 만들지 않아도 된다
-
- 스레드를 생성하는 코드가 없다. 처음에
ExecutorService만 생성하면 된다. -
join()을 사용해서 스레드를 제어하는 코드가 없다.
동작 과정 살펴보기: 작업 중간에 get()
로그 포맷 변경
가독성을 위해
prettyprint를 적용하고,timestamp를 제외했다.
이전 코드에서 future.get()을 통해서 스레드가 완료한 작업의 결과를 반환 받았다. 그러면 작업을 완료하지 못했다면 어떻게 되는 것일까?
이전 예시의 코드를 통해서 Future의 동작 과정을 살펴보자. 이전 코드에서 future.get()을 기준으로 앞뒤로 로그를 찍으면서 future의 값을 확인해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@Slf4j
public class CallableEx2Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(1);
log.info("submit() 호출");
Future<Integer> future = es.submit(new MyCallable());
log.info("future 즉시 반환, future = {}", future);
log.info("future.get(): 블로킹 메서드 호출 시작 -> 메인 스레드는 WAITING");
Integer result = future.get();
log.info("future.get(): 블로킹 메서드 호출 완료 -> 메인 스레드는 RUNNABLE");
log.info("future 완료, future = {}", future);
log.info("future.get() = {}", result);
es.close();
}
private static class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
// Ex1과 동일...
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"message" : "submit() 호출",
"thread_name" : "main"
}
{
"message" : "---Callable 시작---",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "future 즉시 반환, future = java.util.concurrent.FutureTask@6692b6c6[Not completed, task = de.executor_ex.CallableEx2Main$MyCallable@5456afaa]",
"thread_name" : "main"
}
{
"message" : "future.get(): 블로킹 메서드 호출 시작 -> 메인 스레드는 WAITING",
"thread_name" : "main"
}
{
"message" : "Callable result = 30",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "---Callable 종료---",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "future.get(): 블로킹 메서드 호출 완료 -> 메인 스레드는 RUNNABLE",
"thread_name" : "main"
}
{
"message" : "future 완료, future = java.util.concurrent.FutureTask@6692b6c6[Completed normally]",
"thread_name" : "main"
}
{
"message" : "future.get() = 30",
"thread_name" : "main"
}
-
future.get()이전-
future즉시 반환:Not completed를 확인할 수 있다
-
-
future.get()이후-
future완료:Completed normally를 확인할 수 있다
-
생각해보면 Future<Integer> future = es.submit(new MyCallable());에서 MyCallable이 즉시 실행되어 결과를 반환하는 것이 아니다. 해당 작업이 작업 큐로 전해지고, 미래의 어느 시점에서 스레드 풀의 스레드 하나를 할당받아서 작업을 수행한다. 이런 이유로 결과가 즉시 Integer 형태로 반환되는 것이 아니라 Future 객체를 대신 제공해주는 것이다. Future라는 전달한 작업의 미래 결과를 담는다고 보면 된다.
쉽게 말해서, Future는 비동기적으로 수행되는 작업의 결과를 나중에 제공할 “미래의 객체”로 보면 된다. 이를 통해 작업이 완료되었을 때 결과를 가져오거나, 작업이 아직 완료되지 않은 경우 기다리거나, 작업을 취소하는 등의 기능을 제공한다.
그림을 통해서 작동 과정을 더 자세히 살펴보자.
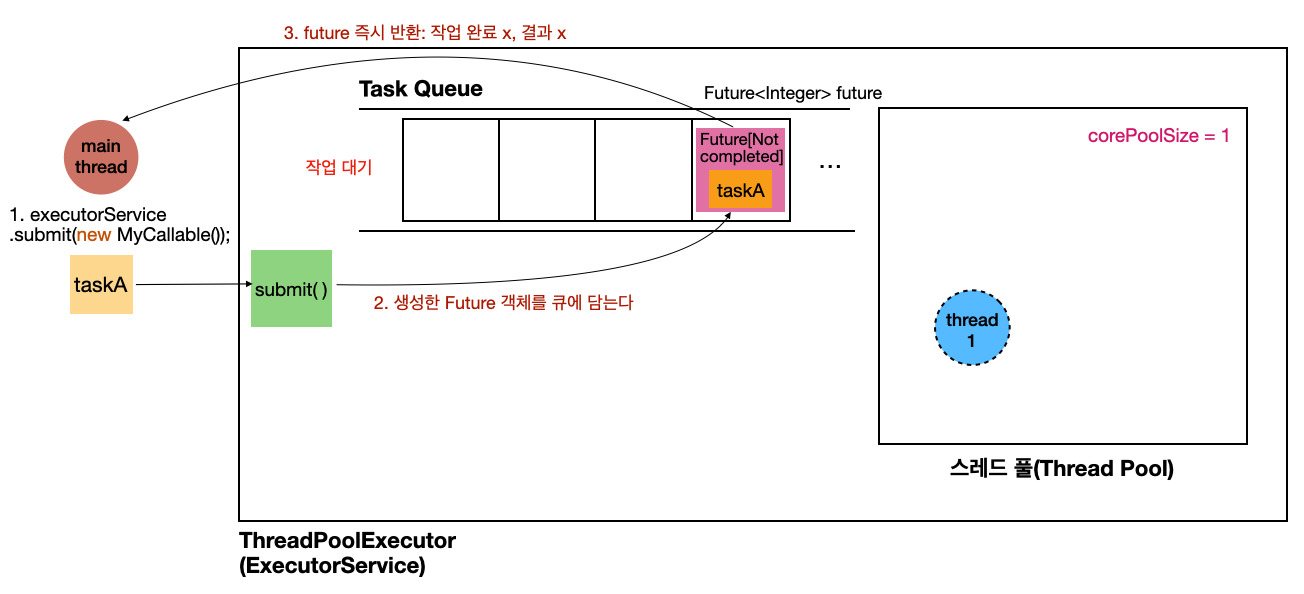 Future 객체 생성
Future 객체 생성
-
main스레드에서submit(new MyCallable())를 호출한다-
new MyCallable()에 해당하는 작업을taskA라고 하자
-
-
ThreadPoolExecutor에서taskA에 대한Future객체를 생성하고 작업 큐에 전달한다- 해당
Future객체 내부에는 작업의 완료 여부, 결과 값, 등을 포함한다
- 해당
- 작업은 완료되지 않았기 때문에 당연히
Not completed상태이다. 이 상태에서future를 반환 받으면 결과 값은 없다. - 여기서 중요한 점은 값만 받을 수 없을 뿐이지,
future를 즉시 반환 받을 수 있다는 것이다.
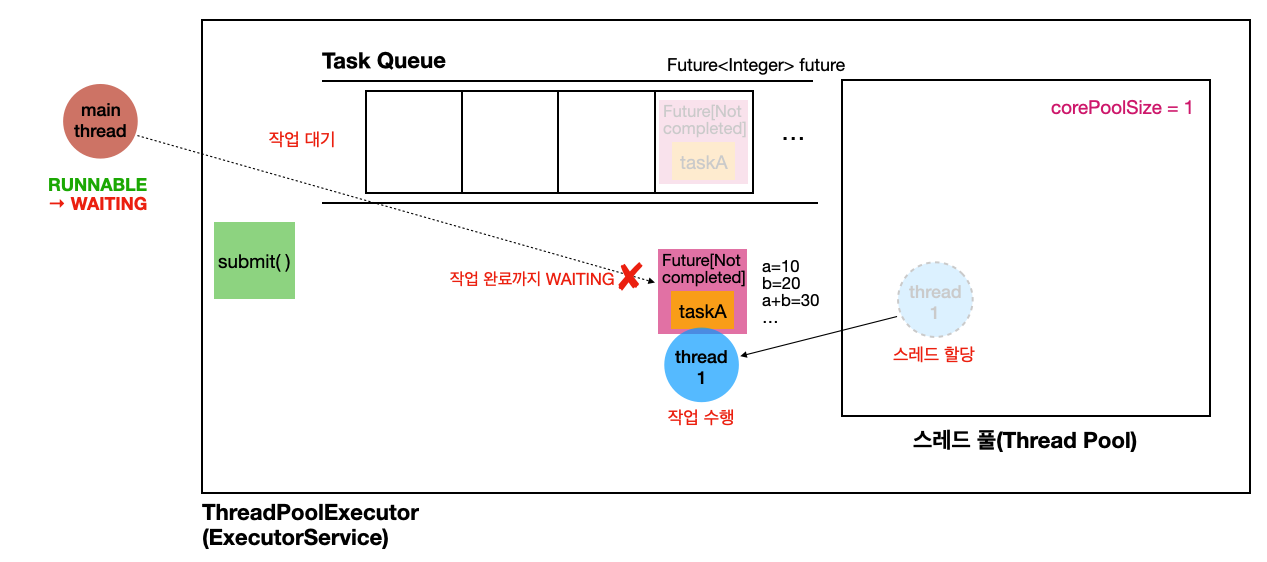 작업 수행
작업 수행
- 작업 큐의
Future객체를 꺼내서 스레드 풀의thread1을 할당받는다. 해당 작업을 수행한다.-
Runnable의run()을 통해call()을 호출하는 방식으로 수행된다
-
-
main스레드에서 작업의 결과를 얻기 위해서future.get()을 호출한다-
Future완료 상태: 대기할 필요 없이 즉시 결과를 반환 받을 수 있다 -
Future작업 수행 상태:main스레드는 작업이 완료될 때 까지 기다린다(main스레드 블로킹 중)- 작업이 수행되는 동안
main스레드의 상태는 WAITING 상태이다
- 작업이 수행되는 동안
-
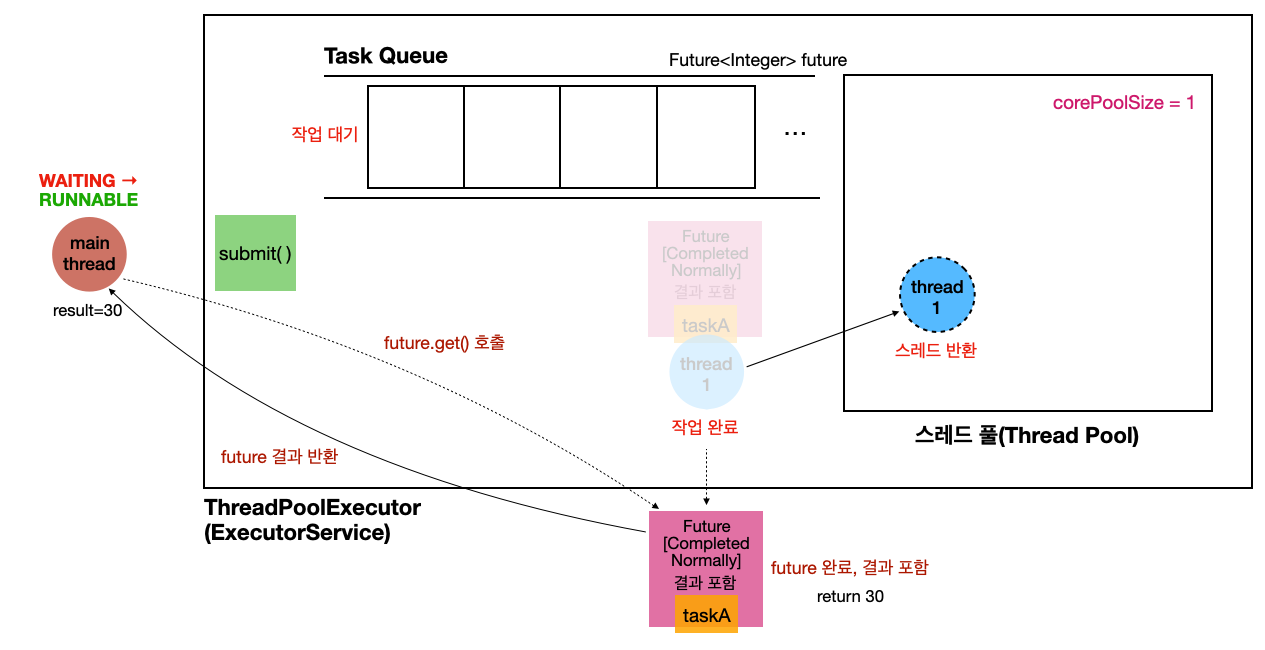 future 결과 반환
future 결과 반환
- 작업이 완료되었다
-
Completed Normally:Future는 완료 상태가 된다, 완료 되었으니 당연히 결과를 포함하고 있다 -
main스레드는 RUNNABLE 상태로 변경된다 -
thread1은 스레드 풀로 다시 반환한다
-
-
main스레드에서 결과를 받는다result = 30
Future 예시 2
이번에는 스레드 수가 2개인 스레드 풀을 만들고, 각 스레드가 10, 20이라는 결과를 반환한다고 해보자. 각 작업은 3초가 소요 된다고 하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
@Slf4j
public class FutureEx3Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 2개의 스레드를 가진 스레드 풀 생성
ExecutorService executor = Executors.newFixedThreadPool(2);
// 첫 번째 작업 정의: 10 반환
Callable<Integer> task1 = () -> {
log.info("---Callable task1 시작, 수행 3초---");
Thread.sleep(3000); // 작업을 시뮬레이션
int result = 10;
log.info("---Callable task1 종료, result = {}---", result);
return result;
};
// 두 번째 작업 정의: 20 반환
Callable<Integer> task2 = () -> {
log.info("---Callable task2 시작, 수행 3초---");
Thread.sleep(3000); // 작업을 시뮬레이션
int result = 20;
log.info("---Callable task2 종료, result = {}---", result);
return result;
};
Future<Integer> future1 = executor.submit(task1);
Future<Integer> future2 = executor.submit(task2);
log.info("future1.get() 호출 - Main: WAITING, 작업 기다림");
Integer result1 = future1.get();
log.info("future2.get() 호출 - Main: RUNNABLE, 즉시 반환 받는 것 가능");
Integer result2 = future2.get();
log.info("future1.get() = {}", result1);
log.info("future2.get() = {}", result2);
int result = result1 + result2;
log.info("result = {}", result);
log.info("main thread end");
executor.close();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
{
"message" : "---Callable task1 시작, 수행 3초---",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "---Callable task2 시작, 수행 3초---",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "future1.get() 호출 - Main: WAITING, 작업 기다림",
"thread_name" : "main"
}
{
"message" : "---Callable task2 종료, result = 20---",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "---Callable task1 종료, result = 10---",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "future2.get() 호출 - Main: RUNNABLE, 즉시 반환 받는 것 가능",
"thread_name" : "main"
}
{
"message" : "future1.get() = 10",
"thread_name" : "main"
}
{
"message" : "future2.get() = 20",
"thread_name" : "main"
}
{
"message" : "result = 30",
"thread_name" : "main"
}
{
"message" : "main thread end",
"thread_name" : "main"
}
- 만약
ExecutorService와Callable을 사용하지 않았다면,join()과 같은 메서드를 사용하면서 코드가 복잡해졌을 것이다.
다음 그림을 통해서 시간 흐름에 따른 동작을 살펴보자.
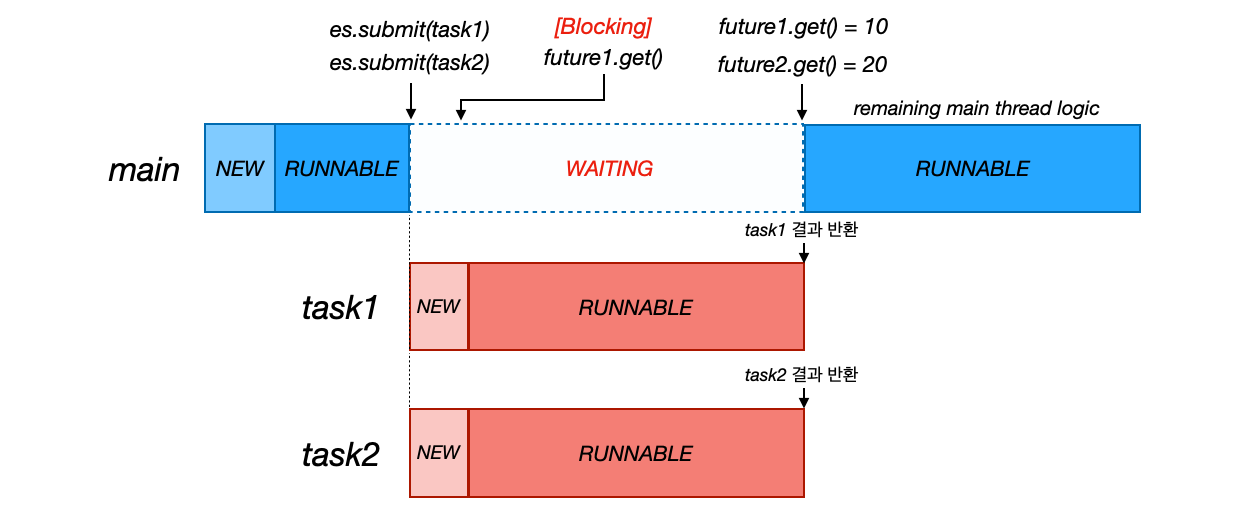 시간에 따른 동작
시간에 따른 동작
-
es.submit(task1),es.submit(task2)로task1,task2는 동시에 수행된다 - 중간에
task1이 끝나지 않았는데future1.get()을 호출하면 요청 스레드(main)는task1이 완료될 때 까지 기다린다(WAITING 상태) - 이후에
future2.get()를 호출한다, 그 동안 작업이 모두 끝났기 때문에 결과를 즉시 반환 받을 수 있다- 이 시점에 대기하고 있는
future1.get()도 결과를 반환 받는다
- 이 시점에 대기하고 있는
Future의 잘못된 사용법
Future를 잘못 활용하는 케이스를 살펴보자.
잘못된 활용 1
1
2
3
4
Future<Integer> future1 = es.submit(task1); // non-blocking
Integer sum1 = future1.get(); // blocking, 2초 대기
Future<Integer> future2 = es.submit(task2); // non-blocking
Integer sum2 = future2.get(); // blocking, 2초 대기
잘못된 활용 2
1
2
Integer sum1 = es.submit(task1).get(); // get()에서 블로킹
Integer sum2 = es.submit(task2).get(); // get()에서 블로킹
두 케이스 모두 작업을 하나 요청 후 바로 결과를 반환 받는 것을 시도하고 있다. task1 시작 - task1 결과 요청 - task2 시작 - task2 결과 요청
이 경우, 다음 그림 처럼 동작하게 된다.
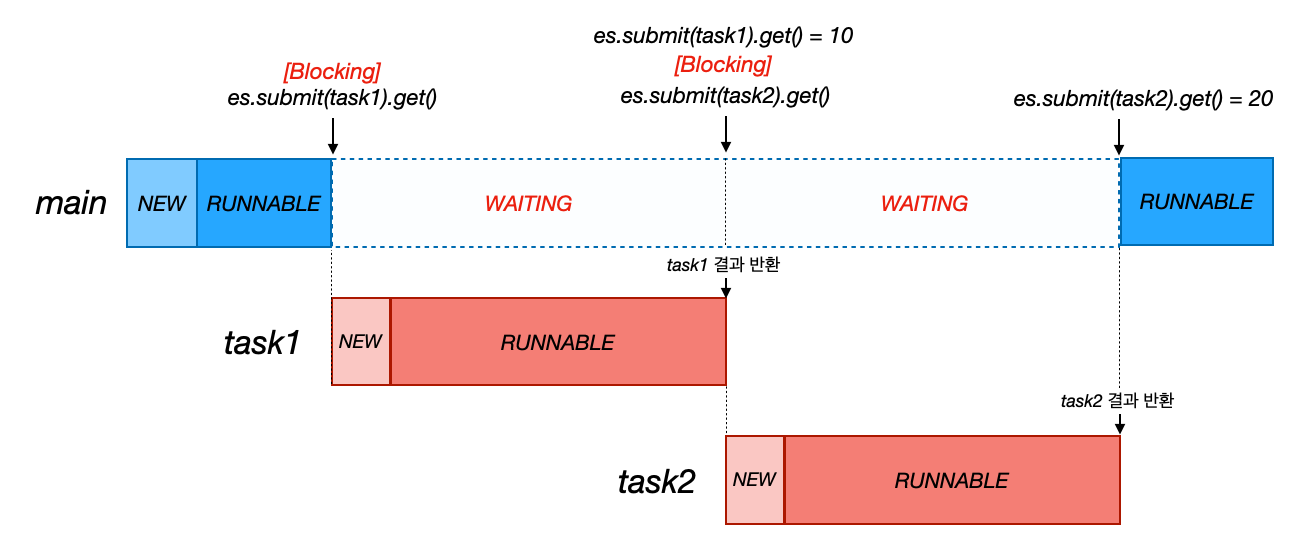 future 잘못된 사용법
future 잘못된 사용법
마치 싱글 스레드 처럼 동작하게 된다. 이는 바람직하지 않다.
4. ExecutorService 종료
ExecutorService의 “우아한 종료(graceful shutdown)”는 스레드 풀을 사용한 작업이 모두 완료될 수 있도록 안전하게 종료하는 방법을 의미한다. 우아한 종료는 스레드 풀에 이미 제출된 작업들이 완료될 때까지 기다리며, 새로운 작업이 제출되지 않도록 하는 방식으로 이루어진다.
ExecutorService의 우아한 종료를 위해 제공되는 두 가지 주요 메서드는 다음과 같다.
-
void shutdown()- 논 블로킹 메서드: 이 메서드를 호출한 스레드는 대기하지 않고 즉시 다음 코드를 호출한다
- 새로운 작업의 제출을 중지하지만, 이미 제출된 작업은 계속 실행된다
- 이 메서드가 호출된 후에는 더 이상 작업을 제출할 수 없으며, 모든 작업이 완료될 때까지 스레드 풀은 실행을 계속한다
- 모든 작업이 완료되면 스레드 풀은 종료된다
-
List<Runnable> shutdownNow()- 논 블로킹 메서드
- 모든 실행 중인 작업을 중단하려 시도하고, 대기 중인 작업 목록을 반환한다
-
shutdown()보다 더 강력한 종료 방법이며, 스레드 풀을 즉시 종료하려는 경우에 사용된다 - 실행 중인 스레드에
interrupt()호출을 통해 인터럽트를 발생시켜 작업을 중단할 수 있다
작업 완료 대기를 위한 메서드는 다음과 같다.
-
boolean awaitTermination(timeout, unit)-
shutdown()이 호출된 후, 모든 작업이 완료될 때까지 대기한다 - 이 메서드는 지정된 시간(
timeout) 내에 스레드 풀이 종료될 때까지 현재 스레드를 차단(block)한다 -
timeout기간 동안 작업이 완료되지 않으면false를 반환하며,true를 반환한 경우는 모든 작업이 정상적으로 완료된 경우이다 -
shutdownNow()를 호출하여 강제 종료를 시도할 수 있다
-
ExecutorService의 상태 확인을 위한 메서드는 다음과 같다.
-
boolean isShutdown()-
shutdown()또는shutdownNow()메서드가 호출된 후ExecutorService가 새로운 작업을 더 이상 받지 않는 상태인지 여부를 확인한다 - 스레드 풀에 종료 명령이 내려졌는지 확인하는 데 사용된다
-
true: 종료 상태에 진입 -
false: 아직 종료되지 않았음
-
-
-
boolean isTerminated()-
ExecutorService내의 모든 작업이 완료되고, 스레드 풀이 완전히 종료되었는지 확인한다-
true: 모든 작업이 완료되어ExecutorService가 완전히 종료되었음을 의미 -
false: 아직 작업이 완료되지 않았거나 스레드 풀이 종료되지 않았음을 의미
-
-
close()
- 자바19부터 도입: https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/util/concurrent/ExecutorService.html#close()
shutdown()을 호출하고, 하루를 기다려도 작업이 완료되지 않으면shutdownNow()를 호출한다- 호출한 스레드에 인터럽트가 발생해도
shutdownNow()가 호출된다- 자바 19 부터
autocloseable인터페이스를 구현하는 것 같다. 아마try-with-resources방식으로 자원 관리가 가능할 것으로 보인다.
다음은 자바 공식 문서에서 보여주는 예시이다.
The following method shuts down an
ExecutorServicein two phases, first by callingshutdownto reject incoming tasks, and then callingshutdownNow, if necessary, to cancel any lingering tasks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void shutdownAndAwaitTermination(ExecutorService pool) {
pool.shutdown(); // Disable new tasks from being submitted
try {
// Wait a while for existing tasks to terminate
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
pool.shutdownNow(); // Cancel currently executing tasks
// Wait a while for tasks to respond to being cancelled
if (!pool.awaitTermination(60, TimeUnit.SECONDS))
System.err.println("Pool did not terminate");
}
} catch (InterruptedException ex) {
// (Re-)Cancel if current thread also interrupted
pool.shutdownNow();
// Preserve interrupt status
Thread.currentThread().interrupt();
}
}
서비스 종료시 기본적으로 우아한 종료를 선택하고, 종료되지 않으면 강제 종료를 하는 방식으로 접근하는 것을 권장한다.
5. 스레드 풀 관리
스레드 풀 속성 알아보기
ExecutorService는 다양한 구현체들을 제공한다. 몇 가지 구현체들을 살펴보자.
-
ThreadPoolExecutor-
corePoolSize- 기본적으로 유지되는 스레드의 수
- 초기에는 이 수만큼의 스레드가 생성되며, 작업이 있을 때만 활성화된다
-
maximumPoolSize- 스레드 풀에서 허용하는 최대 스레드 수
- 작업 큐가 꽉 차면, 이 수만큼의 스레드가 생성되어 작업을 처리한다
-
keepAliveTime-
corePoolSize이상의 여분의 스레드가 일정 시간 동안 작업이 없을 경우 종료되는 시간
-
-
workQueue- 작업이 대기하는 큐
-
BlockingQueue인터페이스를 구현한다.
-
rejectedExecutionHandler- 작업이 스레드 풀에서 처리될 수 없을 때 실행되는 핸들러
- 기본적으로
AbortPolicy,CallerRunsPolicy,DiscardPolicy,DiscardOldestPolicy를 제공한다 - 이 속성은 뒤에서 자세히 알아볼 예정이다
-
-
ScheduledThreadPoolExecutor- 주기적이거나 지연된 작업을 처리하기 위한 스레드 풀이다
-
ScheduledExecutorService인터페이스를 구현한다 -
스케줄링 기능
-
schedule(),scheduleAtFixedRate(),scheduleWithFixedDelay()메서드를 통해 작업을 일정 시간 후에 실행하거나 주기적으로 실행할 수 있다
-
-
사용 상황
- 타이머, 주기적인 작업 실행 등이 필요한 상황에서 사용할 수 있다
-
ForkJoinPool-
Fork/Join프레임워크를 기반으로 하는 구현체로, 작업을 작은 단위로 나누어 병렬로 처리한다 -
parallelism- 동시에 실행될 수 있는 최대 작업 수
- 기본적으로
Runtime.getRuntime().availableProcessors()를 사용하여 시스템의 코어 수를 기반으로 설정된다
-
작업 분할:
RecursiveTask와RecursiveAction을 사용하여 작업을 작은 단위로 나누고 병렬로 처리할 수 있다 - 워크 스틸링: 작업이 완료되지 않은 스레드가 다른 스레드의 작업 큐에서 남은 작업을 가져와 처리하는 방식으로, 작업의 균등한 분배를 보장한다
-
사용 상황
- 대규모 데이터 처리, 병렬 알고리즘 실행, 등에 있어서 하나의 작업이 다른 작업과 작업 속도가 차이가 난다면 효과적일 수 있다
-
이 포스트에서는 ThreadPoolExecutor를 위주로 살펴볼 것이다. 다음의 스레드 풀을 사용한다고 하자.
-
BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<>(2)- 작업 큐는
ArrayBlockingQueue로 구현 - 크기는
2, 최대 2개의 작업까지 보관할 수 있다
- 작업 큐는
-
new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, taskQueue)corePoolSize=2maximumPoolSize=4-
keepAliveTime=3000- 단위는
TimeUnit.MILLISECONDS
- 단위는
- 사용할
BlockingQueue는 위에서 생성한taskQueue
이제 작업을 실행해보면서 스레드 풀에서 스레드의 생성 추이를 살펴보자.
초기 상태 ~ corePoolSize
우리가 이전에 만든 ExecutorUtils의 printState를 오버로딩하는 메서드를 만들자. taskName이 표시되도록 만들자. 다음 코드에서 사용하는 RunnableTask는 작업을 1초 동안 수행하는 작업이라고 하자.
스레드를 아무것도 생성하지 않은 초기 상태에서 corePoolSize의 수 만큼 작업을 실행해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Slf4j
public class ThreadPoolEx1Main {
public static void main(String[] args) {
BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<>(2);
ExecutorService executor = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, taskQueue);
printState(executor);
executor.execute(new RunnableTask("task1"));
printState(executor, "task1");
executor.execute(new RunnableTask("task2"));
printState(executor, "task2");
executor.close();
log.info("--shutdown--");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
{
"message" : "[pool = 0, active = 0, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 -> [pool = 1, active = 1, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 시작",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "task2 -> [pool = 2, active = 2, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task2 시작",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "task1 완료",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "task2 완료",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "--shutdown--",
"thread_name" : "main"
}
초기 상태의 스레드 풀에서는 스레드가 생성되지 않았다. 작업이 추가될 때마다 스레드 풀의 스레드 개수와 active 스레드 개수가 증가하는 것을 확인할 수 있다.
corePoolSize ~ maximumPoolSize
corePoolSize=2에서 maximumPoolSize=4의 수 만큼 작업을 실행해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Slf4j
public class ThreadPoolEx1Main {
public static void main(String[] args) {
BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<>(2);
ExecutorService executor = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, taskQueue);
printState(executor);
executor.execute(new RunnableTask("task1"));
printState(executor, "task1");
executor.execute(new RunnableTask("task2"));
printState(executor, "task2");
executor.execute(new RunnableTask("task3"));
printState(executor, "task3");
executor.execute(new RunnableTask("task4"));
printState(executor, "task4");
executor.close();
log.info("--shutdown--");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
{
"message" : "[pool = 0, active = 0, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 -> [pool = 1, active = 1, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 시작",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "task2 -> [pool = 2, active = 2, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task3 -> [pool = 2, active = 2, queuedTasks = 1, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task2 시작",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "task4 -> [pool = 2, active = 2, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
// 작업 시작~완료 관련 로그...
{
"message" : "--shutdown--",
"thread_name" : "main"
}
보면 task3와 task4는 작업 큐에 보관된다. 스레드의 개수는 아직 2개로, 새롭게 생성되지 않은 것을 확인할 수 있다.
maximumPoolSize ~
이번에는 maxiumPoolSize=4 보다 많은 작업을 추가해보자.
먼저 작업의 개수를 6개 까지 늘려보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Slf4j
public class ThreadPoolEx1Main {
public static void main(String[] args) {
BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<>(2);
ExecutorService executor = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, taskQueue);
printState(executor);
// 기존 task1~4
// task5,6 추가
executor.execute(new RunnableTask("task5"));
printState(executor, "task5");
executor.execute(new RunnableTask("task6"));
printState(executor, "task6");
executor.close();
log.info("--shutdown--");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
{
"message" : "[pool = 0, active = 0, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 -> [pool = 1, active = 1, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 시작",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "task2 -> [pool = 2, active = 2, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task3 -> [pool = 2, active = 2, queuedTasks = 1, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task2 시작",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "task4 -> [pool = 2, active = 2, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task5 -> [pool = 3, active = 3, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task5 시작",
"thread_name" : "pool-1-thread-3"
}
{
"message" : "task6 -> [pool = 4, active = 4, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
// 작업 시작~완료 관련 로그...
{
"message" : "--shutdown--",
"thread_name" : "main"
}
현재 작업 큐(ArrayBlockingQueue<>(2))에는 최대 2개의 작업을 보관할 수 있다. 작업 큐의 용량을 넘어선 작업을 요청하니, 이제서야 스레드 풀의 스레드 개수가 증가하는 것을 확인할 수 있다. 이제 현재 스레드 풀의 스레드 갯수는 maxiumPoolSize=4에 도달했다. 쉽게 말해서서, 작업 큐에도 보관하지 못하는 상황이 와야 스레드의 개수가 늘어나기 시작한다.
만약 작업을 하나 더 추가해서 총 7개의 작업을 실행하면 어떻게 될까? 코드로 한번 확인해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Slf4j
public class ThreadPoolEx1Main {
public static void main(String[] args) {
BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<>(2);
ExecutorService executor = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, taskQueue);
printState(executor);
// 기존 task1~6
// task 하나 더 추가
executor.execute(new RunnableTask("task7"));
printState(executor, "task7");
executor.close();
log.info("--shutdown--");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
{
"message" : "[pool = 0, active = 0, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 -> [pool = 1, active = 1, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task1 시작",
"thread_name" : "pool-1-thread-1"
}
{
"message" : "task2 -> [pool = 2, active = 2, queuedTasks = 0, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task2 시작",
"thread_name" : "pool-1-thread-2"
}
{
"message" : "task3 -> [pool = 2, active = 2, queuedTasks = 1, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task4 -> [pool = 2, active = 2, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task5 -> [pool = 3, active = 3, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
{
"message" : "task6 -> [pool = 4, active = 4, queuedTasks = 2, completedTasks = 0]",
"thread_name" : "main"
}
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task de.executor_ex.RunnableTask@52815fa3 rejected from java.util.concurrent.ThreadPoolExecutor@74f6c5d8[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]
at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2081)
at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:841)
at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1376)
at de.executor_ex.ThreadPoolEx1Main.main(ThreadPoolEx1Main.java:38)
스레드의 개수가 maxiumPoolSize=4 만큼 생성되고, 작업 큐도 가득 차 있는 상태에서 작업을 추가하면 결국에 RejectedExecutionException이 발생한다.
keepAliveTime 초과하는 경우
이번에는 작업이 모두 완료된 직후의 상태, keepAliveTime=3000을 초과하는 경우의 상태, 그리고 종료를 한 바로 이후의 상태를 살펴보자. task7은 try-catch로 처리하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
@Slf4j
public class ThreadPoolEx1Main {
public static void main(String[] args) {
BlockingQueue<Runnable> taskQueue = new ArrayBlockingQueue<>(2);
ExecutorService executor = new ThreadPoolExecutor(2, 4, 3000, TimeUnit.MILLISECONDS, taskQueue);
printState(executor);
// 기존 task1~6
try {
executor.execute(new RunnableTask("task7"));
printState(executor, "task7");
} catch (RejectedExecutionException e) {
log.error("maximumPoolSize 한계, workQueue 가득 참, task7 거절", e);
}
// 작업 수행 완료
log.info("---작업 수행 완료---");
ThreadUtils.sleep(3000);
printState(executor);
// keepAliveTime 3초 초과 상태
log.info("---keepAliveTime 초과---");
ThreadUtils.sleep(3000);
printState(executor);
// 종료 바로 이후 상태
executor.close();
log.info("---shutdown---");
printState(executor);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"message" : "---작업 수행 완료---",
"thread_name" : "main"
}
{
"message" : "[pool = 4, active = 0, queuedTasks = 0, completedTasks = 6]",
"thread_name" : "main"
}
{
"message" : "---keepAliveTime 초과---",
"thread_name" : "main"
}
{
"message" : "[pool = 2, active = 0, queuedTasks = 0, completedTasks = 6]",
"thread_name" : "main"
}
{
"message" : "---shutdown---",
"thread_name" : "main"
}
{
"message" : "[pool = 0, active = 0, queuedTasks = 0, completedTasks = 6]",
"thread_name" : "main"
}
-
작업 완료 직후: 아직
keepAliveTime을 초과하지 않았기 때문에 스레드 4개가 모두 살아있다 -
keepAliveTime초과:keepAliveTime을 초과했기 때문에,corePoolSize를 초과한 초과 스레드는 모두 스레드 풀에서 제거된다 - 종료 이후: 종료 이후에는 스레드 풀이 종료되고 스레드도 모두 제거된다
6. 스레드 풀 관리 전략
자바에서 스레드 풀을 생성하기 위해 제공하는 대표적인 세 가지 전략은 newFixedThreadPool, newCachedThreadPool, 그리고 newSingleThreadExecutor이다. 각 전략은 서로 다른 요구 사항에 맞게 설계되었으며, 다양한 시나리오에서 활용될 수 있다.
고정 풀 전략: newFixedThreadPool()
1
2
3
4
5
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
-
newFixedThreadPool(int nThreads)- 고정된 수의 스레드를 유지하는 스레드 풀을 생성한다
- 스레드 풀은 항상
nThreads개의 스레드를 유지하며, 작업이 제출될 때마다 이러한 스레드 중 하나가 사용된다 - 작업 큐 사이즈에는 제한이 없다(
LinkedBlockingQueue) - 스레드 풀이 가득 차 있는 상태에서 추가 작업이 제출되면, 작업은 작업 큐에 쌓이고, 이전 작업이 완료되면 대기 중인 작업이 실행된다
고정 풀 전략의 특징은 다음과 같다.
-
고정된 스레드 수: 설정된 스레드 수가 항상 유지됩니다. 이 수는
nThreads로 지정 - 성능 예측 가능성: 스레드 수가 고정되어 있기 때문에 CPU 및 메모리 사용량이 예측 가능하고, 리소스 관리가 용이하다
- 큐 사이즈에 제한이 없어서 작업을 많이 담아둘 수 있다
고정 풀 전략의 사용에서 주의할 점은 다음과 같다.
- 갑작스런 요청 증가: 사용자 수가 예측이 되는 경우 안정적으로 서비스 운영이 가능하지만, 갑작스러운 사용자 또는 요청 폭증에 대응하기 힘들다.
- 응답이 느린 상태지만 서버의 CPU, 메모리 사용량이 늘어나지 않은 경우: 보통 고정 풀 전략이 원인이다. 사용자는 증가하는데 스레드의 수는 고정되어 있어서 작업 큐에 쌓여있을 확률이 높다.
고정 풀 전략은 사용자나 요청의 수가 예측이 가능하면 문제가 되지 않지만, 사용자가 늘어나는 상황에서는 유연하게 대응하기 힘들 수 있다.
캐시 풀 전략: newCachedThreadPool()
1
2
3
4
5
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
-
newCachedThreadPool()- 필요에 따라 스레드를 동적으로 생성하고, 사용되지 않는 스레드를 재사용하는 스레드 풀을 생성한다
- 처음에는 스레드 풀이 비어 있다가 작업이 제출되면 새로운 스레드를 생성하여 작업을 처리한다
- 이전에 생성된 스레드는 일정 시간(기본 60초) 동안 재사용될 수 있으며, 이후에도 사용되지 않으면 제거된다
- 큐에 작업을 저장하지 않는다(
SynchronousQueue)- 생산자의 요청을 스레드 풀의 소비자 스레드가 직접 받아서 처리한다
- 모든 요청이 대기하지 않고 스레드가 바로바로 처리한다(빠른 처리)
SynchronousQueue
BlockingQueue의 구현체 중 하나이다.
- 저장 공간이 없다
- 내부에 데이터를 저장하지 않는다
- 생산자에 의해 데이터가 큐에 삽입되면, 반드시 그 데이터가 소비자에 의해 즉시 처리되어야 한다. 만약 소비자가 준비되어 있지 않다면, 생산자는 대기 상태에 놓인다.
- 핸드오프 (Hand-off) 메커니즘
- 생산자(즉, 데이터를 큐에 삽입하려는 스레드)가 데이터를 삽입할 때까지 대기하며, 소비자(즉, 데이터를 큐에서 가져오려는 스레드)가 준비될 때까지 기다린다
- 쉽게 말해서, 생산자에 의해 데이터가 큐에 삽입되면, 반드시 그 데이터가 소비자에 의해 즉시 처리되어야 한다. 만약 소비자가 준비되어 있지 않다면, 생산자는 대기 상태에 놓인다.
- 생산자와 소비자가 동시에 만나 데이터를 전달하는 방식으로 동작한다
- 이 메커니즘 덕분에
SynchronousQueue는 매우 빠르게 데이터 전송을 할 수 있으며, 특히 생산자와 소비자 간의 작업을 밀접하게 동기화할 필요가 있을 때 유용하다
캐시 풀 전략의 특징은 다음과 같다.
- 동적 스레드 생성: 작업이 많을 때는 스레드가 계속 추가되며, 작업이 줄어들면 스레드 수가 자동으로 감소한다
- 높은 유연성: 작업의 양이 급격히 늘어나거나 줄어드는 상황에서 유용하다
- 빠른 처리: 기본 스레드가 없는 대신, 작업 요청이 오면 초과 스레드로 작업을 바로 처리하기 때문에 빠른 처리가 가능하다
- 서버 자원 최대로 사용: 초과 스레드 수에 제한이 없기 때문에 CPU, 메모리만 허용한다면 시스템의 자원을 최대로 사용할 수 있다
캐시 풀 전략 사용 시 주의점은 다음과 같다.
-
시스템 자원 전부 사용: 작업 수에 맞춰서 스레드 수가 변하기 때문에, 한꺼번에 요청이 폭증하면 서버의 자원을 모두 소모하고 서버가 다운될 수 있다
- 이런 유연성은 장점이 될 수 있지만, 동시에 단점도 될 수 있다
- 서버가 감당할 수 있는 임계점을 넘지 않도록 잘 대응해야 한다
사용자 정의 풀 전략
고정 풀 전략과 캐시 풀 전략의 한계를 다시 살펴보자.
-
고정 풀 전략의 한계
- 스레드 수 고정: 작업량이 급증하거나 감소할 때, 고정된 수의 스레드는 비효율적일 수 있다. 작업량이 많을 때는 스레드가 부족해 대기 시간이 길어지고, 작업량이 적을 때는 스레드가 불필요하게 많은 자원을 소비할 수 있다.
-
캐시 풀 전략의 한계
- 스레드 과도 생성: 작업량이 급증할 때, 캐시 풀은 무제한으로 스레드를 생성할 수 있으므로 시스템 자원을 초과해 사용할 위험이 있다. 이로 인해 OOM(Out of Memory)와 같은 문제가 발생할 수 있다.
이런 문제를 해결하기 위해서 사용자 정의 풀 전략을 통해서 상황을 세분화 해서 대응할 수 있다.
코드를 통해서 알아보자. 다음 코드는 요청의 수를 다음과 같이 세분화 해서 각 요청 수 별로 결과를 살펴 볼 것이다.
-
일반:
TASK_SIZE=600- 작업 큐에는
500, 기본 스레드 수는100이기 때문에 감당 가능하다
- 작업 큐에는
-
긴급:
EMERGENT_TASK_SIZE=700- 작업 큐
500, 기본 스레드 수100, 최대 스레드 수200이기 때문에 초과 스레드100개를 만들어서 대응할 수 있다
- 작업 큐
-
요청 거절:
REJECT_TASK_SIZE=701- 초과 스레드
100가 넘어사면 최대 스레드 수를 넘어간다. 요청을 거절한다.
- 초과 스레드
코드를 한번 실행해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
@Slf4j
public class ThreadPoolStrategyMain {
// 요청 수
static final int TASK_SIZE = 600; // 1. 요청 증가 없는 평소의 상태
static final int EMERGENT_TASK_SIZE = 700; // 2. 요청 폭증 상태
static final int REJECT_TASK_SIZE = 701; // 3. 요청 폭증이 너무 많아서, 일정 수준 부터는 요청 거절
public static void main(String[] args) {
// 코어 스레드 수: 100, 최대 스레드 수: 200, keepAliveTime: 60초
int corePoolSize = 100;
int maximumPoolSize = 200;
long keepAliveTime = 60;
// 작업 큐: 최대 500개의 작업을 수용할 수 있는 큐
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(500);
// 스레드 풀 생성
ThreadPoolExecutor customThreadPool = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime, TimeUnit.SECONDS,
workQueue);
log.info("==사용자 정의 스레드 풀 생성==");
printState(customThreadPool);
// 시작 시간
long startMs = System.currentTimeMillis();
for (int i = 1; i <= TASK_SIZE; i++) {
String taskName = "task" + i;
try {
customThreadPool.execute(new RunnableTask(taskName));
printState(customThreadPool, taskName);
} catch (RejectedExecutionException e) {
log.error("{}: ",taskName, e);
}
}
// 종료
customThreadPool.close();
// 끝나는 시간
long endMs = System.currentTimeMillis();
log.info("time: " + (endMs - startMs));
}
}
-
TASK_SIZE로 실행- 시간
6047ms이 소요
- 시간
-
EMERGENT_TASK_SIZE로 실행- 시간
3997ms소요 - 작업의 수는 늘었는데 소요 시간이 줄어든 이유는 초과 스레드까지 합세해서 요청을 처리하기 때문이다
- 시간
정리하자면, 상황에 맞춰어서 기본 스레드 수와 최대 스레드 수를 정하고, 서버가 감당할 수 없는 만큼 요청이 몰리면 특정 임계점 부터는 요청을 거절하고 사용자에게 메세지를 보내는 방식으로 대응할 수 있다.
LinkedBlockingQueue사용시 주의점기본 생성자로 만든
LinkedBlockingQueue는 무한대의 사이즈를 가지기 때문에 작업 큐가 가득차지 않는다. 작업 큐가 가득 차지 않는 다는 뜻은maximumPoolSize를 활용할 수 없다는 뜻이고,maximumPoolSize를 활용할 수 없다는 뜻은 세분화 해서 대응할 수 없다는 뜻이다.
7. 스레드 풀 예외 처리 정책: RejectedExecutionHandler
예외 처리 정책 소개
스레드 풀에서 예외가 발생했을 때 이를 어떻게 처리할지 정의하는 것이 매우 중요하다. 자바의 ThreadPoolExecutor 클래스는 작업이 큐에 제출될 때, 큐가 가득 차거나 스레드 풀의 최대 용량에 도달했을 때 발생할 수 있는 예외 상황을 처리하기 위한 다양한 예외 처리 정책(RejectedExecutionHandler)을 제공한다.
제공하는 정책은 다음과 같다.
-
AbortPolicy(기본 정책)
-
동작: 작업이 거부되면
RejectedExecutionException예외를 던진다- 예외를 잡아서 작업을 포기하거나, 다시 시도하거나, 사용자에게 알리거나, 등 필요한 로직을 구현하면 된다
- 사용 사례: 예외 상황에서 즉시 작업을 중단하고 오류를 알리려는 경우에 적합하다. 이는 개발자가 오류를 감지하고 적절한 조치를 취할 수 있도록 한다.
- 기본 정책이기 때문에, 정책을 생략하는 경우
AbortPolicy로 동작한다
-
동작: 작업이 거부되면
-
DiscardPolicy
- 동작: 작업이 거부될 경우, 아무런 예외도 발생시키지 않고 작업을 버린다.
- 사용 사례: 시스템이 과부하 상태에 있을 때, 덜 중요한 작업을 포기하고 시스템의 안정성을 유지하려는 경우에 적합하다. 그러나 작업이 손실될 수 있으므로 신중히 사용해야 한다.
-
DiscardOldestPolicy
- 동작: 큐에서 가장 오래된 작업을 제거하고, 새 작업을 큐에 삽입한다
- 사용 사례: 최신 작업이 더 중요하다고 판단되며, 오래된 작업을 희생해서라도 새로운 작업을 처리해야 하는 상황에서 유용하다
- DiscardPolicy와 마찬가지로 작업 손실의 위험이 있다
-
CallerRunsPolicy
- 동작: 작업이 거부될 경우, 해당 작업을 호출한 스레드에서 직접 실행한다. 즉, 새로운 스레드를 생성하거나 기존 스레드를 재사용하지 않고, 호출자 스레드가 작업을 처리하게 하는 것이다.
- 사용 사례: 큐가 가득 차더라도 작업이 포기되지 않고 반드시 처리되어야 하는 상황에서 사용될 수 있다. 다만, 호출자 스레드가 추가적인 작업을 처리하게 되어 전체 시스템 성능에 영향을 줄 수 있다. 쉽게 말해서, 작업을 요청하는 스레드가 느려질 수 있다.
-
RejectedExecutionHandler(사용자 정의 정책)
-
RejectedExecutionHandler인터페이스를 구현 하여 자신만의 거절 처리 전략을 정의할 수 있다
-
다음 예시를 통해 사용법을 알아보자.
1
2
3
4
ExecutorService executor = new ThreadPoolExecutor(1, 1,
0, TimeUnit.SECONDS,
new SynchronousQueue<>(),
new ThreadPoolExecutor.CallerRunsPolicy());
- 가장 뒤에
new ThreadPoolExecutor.CallerRunsPolicy()속성을 추가해서 사용한다 - 아무 속성도 지정하지 않으면 기본 정책인
AbortPolicy()로 동작한다
사용자 정의 정책: RejectedExecutionHandler
사용자 정의 정책을 구현하는 방법은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("Task " + r.toString() + " rejected. Retrying...");
try {
// 일정 시간 대기 후 재시도
Thread.sleep(1000);
executor.execute(r);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
-
RejectedExecutionHandler는 스레드 풀이 작업을 거부할 때 그 상황을 처리하기 위한 정책을 정의하는 인터페이스이다- 이 인터페이스는
void rejectedExecution(Runnable r, ThreadPoolExecutor executor)이라는 하나의 메서드를 가지고 있다
- 이 인터페이스는
- 사용자 정의 정책을 통해서 시스템의 요구 사항에 맞는 거절 정책을 구현할 수 있다
Comments powered by Disqus.