(MongoDB - 2) 몽고DB의 기본적인 CRUD 연산
몽고DB 기본적인 사용법
1. MongoDB Query Language(MQL)
mongosh 명령어 공식 문서 : https://www.mongodb.com/docs/mongodb-shell/run-commands/
MongoDB CRUD 공식 문서 : https://www.mongodb.com/docs/manual/crud/
이제 몽고DB를 사용해보자.
관례(Naming Convention)
- 데이터베이스
- 소문자
- 특수문자 지양
- 컬렉션
- 소문자
- 단수가 아닌 복수 사용
- 필드
- 캐멀케이스(CamelCase) 사용
- 특수문자 지양
- 인덱스
- 소문자
xxx_index같은 형식 사용
몇가지 명령어
db.help()
db객체에 대한 일반적인 메서드 리스트와 설명 출력
show dbs
- 몽공DB 서버내에 존재하는 모든 데이터베이스에 대한 목록
show collections
- 현재 사용하는 데이터베이스 내에 존재하는 모든 컬렉션에 대한 목록
2. 데이터베이스 생성
1
use shop
use {dbname}dbname이라는 명시한 데이터베이스 이름으로 새로운 데이터베이스를 생성한다만약 기존에 존재하는 데이터베이스라면 해당 데이터베이스를 이용한다
- 예)
use shop으로shop이라는 이름의 데이터베이스를 생성하고 사용한다
3. 컬렉션(Collection) 생성, 삭제
1
2
3
4
5
6
7
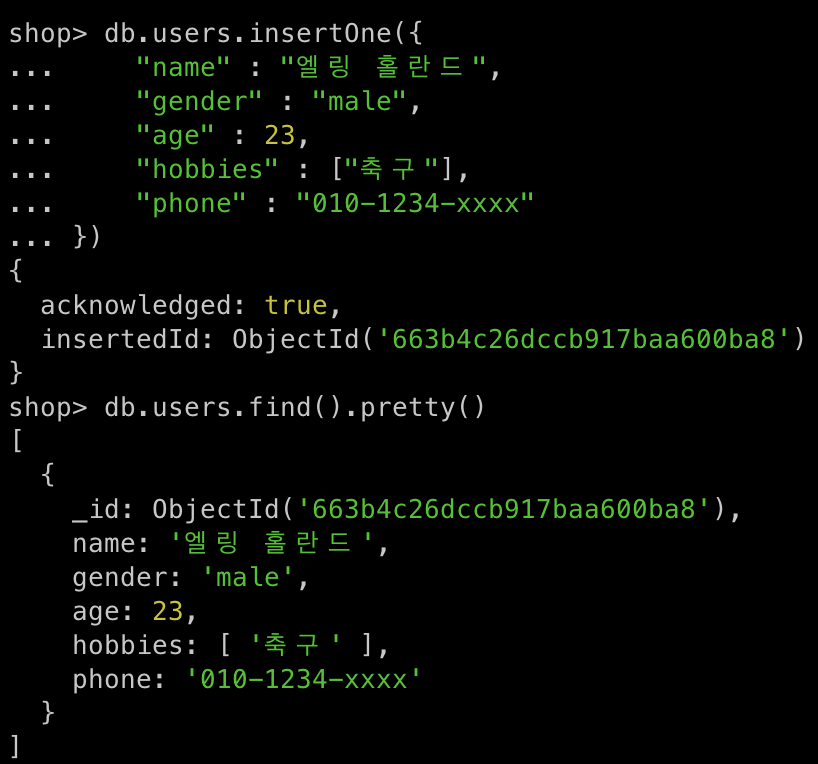
db.users.insertOne({
"name" : "엘링 홀란드",
"gender" : "male",
"age" : 23,
"hobbies" : ["축구"],
"phone" : "010-1234-xxxx"
})
-
db.collectionName.insertOne({data}, options)- 만약 해당 컬렉션이 없다면 컬렉션을 생성하고 명시한 데이터를 이용한 도큐먼트가 생성됨
- 쉽게 말해서 컬렉션이 존재하지 않으면 명시한 컬렉션 이름에 대한 도큐먼트를 처음 생성할 때 해당 컬렉션도 생성된다
- 컬렉션이 있으면 해당 컬렉션안에 도큐먼트를 생성한다
db.createCollection("컬렉션명")
- 명시한 컬렉션명으로 비어있는 컬렉션을 생성한다
- 뒤에서 더 자세히 다루겠지만,
schema validation과 같은 더 자세한 설정을 하고 싶을 때 사용할 수 있다
db.collectionName.drop()
- 명시한 컬렉션을 삭제한다
4. 도큐먼트(Document) 생성
4.1 insertOne()
syntax
db.collectionName.insertOne({data}, options)
- 위에서도 설명했듯이 제공한 데이터로 컬렉션안에 단일 도큐먼트를 생성(입력)한다
- 만약 컬렉션이 존재하지 않으면 명시한 컬렉션명으로 컬렉션을 생성하고 도큐먼트를 생성한다
4.2 insertMany()
syntax
예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
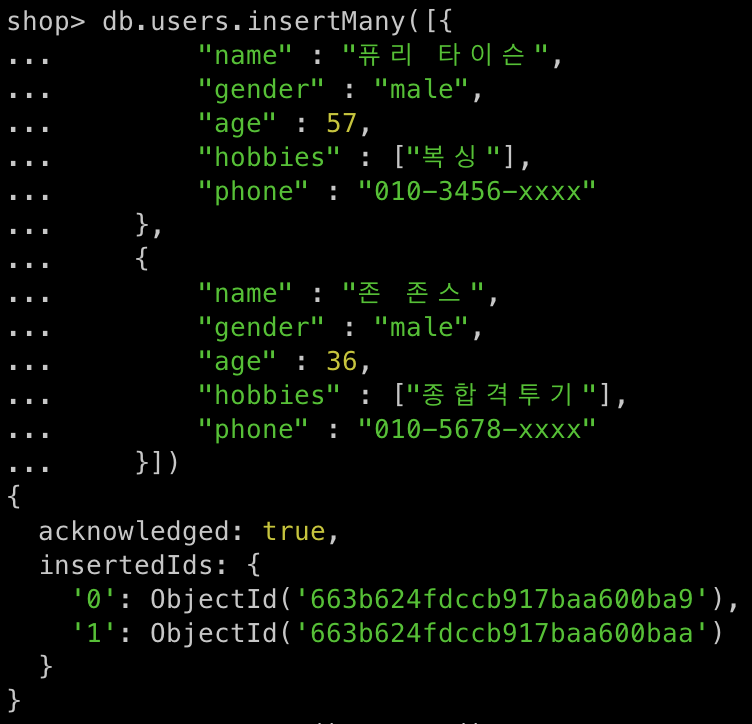
db.users.insertMany([{
"name" : "퓨리 타이슨",
"gender" : "male",
"age" : 57,
"hobbies" : ["복싱"],
"phone" : "010-3456-xxxx"
},
{
"name" : "존 존스",
"gender" : "male",
"age" : 36,
"hobbies" : ["종합격투기"],
"phone" : "010-5678-xxxx"
}])
-
db.collectionName.insertMany([{doc1}, {doc2}..], options)- 컬렉션안에 다수의 도큐먼트를 생성(입력)한다
4.3 중첩 도큐먼트(Embedded, Nested)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
db.users.insertMany([{
"name" : "김연아",
"gender" : "female",
"age" : 33,
"hobbies" : ["피겨 스케이팅"],
"phone" : "010-7891-xxxx",
"address" : {
"country" : "South Korea",
"city" : "Seoul",
"district" : "Heukseok-dong"
}
},
{
"name" : "오타니 쇼헤이",
"gender" : "male",
"age" : 29,
"hobbies" : ["야구"],
"phone" : "010-7654-xxxx",
"address" : {
"country" : "United States of America",
"state" : "Hawaii",
"district" : "Kaunaoa Dr, Waimea"
}
}])
- 도큐먼트안에 도큐먼트가 들어간 중첩된 형태로 사용가능하다
- 몽고DB는 도큐먼트 중첩을
100층까지 제한한다 - 데이터가 적을때는 크게 상관없지만, 데이터가 많아지면 이런 중첩 도큐먼트들이 성능에 대한 오버헤드를 발생시킬수 있다
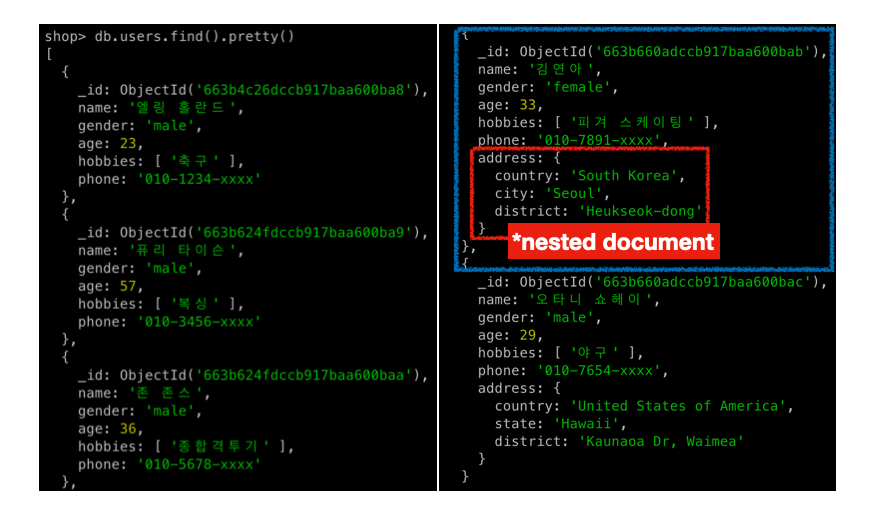
- 필드는 도큐먼트로 이루어진 배열이 될 수 있다
- 예:
[{doc1}, {doc2}, ... {docN}]
- 예:
도큐먼트 생성은 위의 방법 외에도, 다른 메서드에 특정 옵션을 추가해서 사용할 수도 있다.
- 예)
db.collectionName.updateOne()에upsert:true옵션을 사용하면 도큐먼트 생성가능 - 쉽게 설명하자면,
upsert:true를 사용해서 업데이트를 하면, 도큐먼트가 존재하는 경우 해당 도큐먼트에 대한 업데이트 작업을 수행하고, 존재하지 않으면 해당 업데이트 작업 내용으로 도큐먼트를 생성한다
insert()라는 메서드도 존재했으나, 지금은 deprecated 되었다.
4.4 ordered 옵션
기본적으로 몽고DB는 작업이 실패하면, 실패한 작업부터 모든 작업을 중단한다. 쉽게 이야기 하자면 성공한 작업은 정상적으로 반영되지만, 실패한 작업 부터는 전체 작업이 중단되기 때문에 뒤의 작업이 정상적으로 수행될 수 있어도 반영되지 않는다.
다음 그림으로 이해하면 편할 것이다.
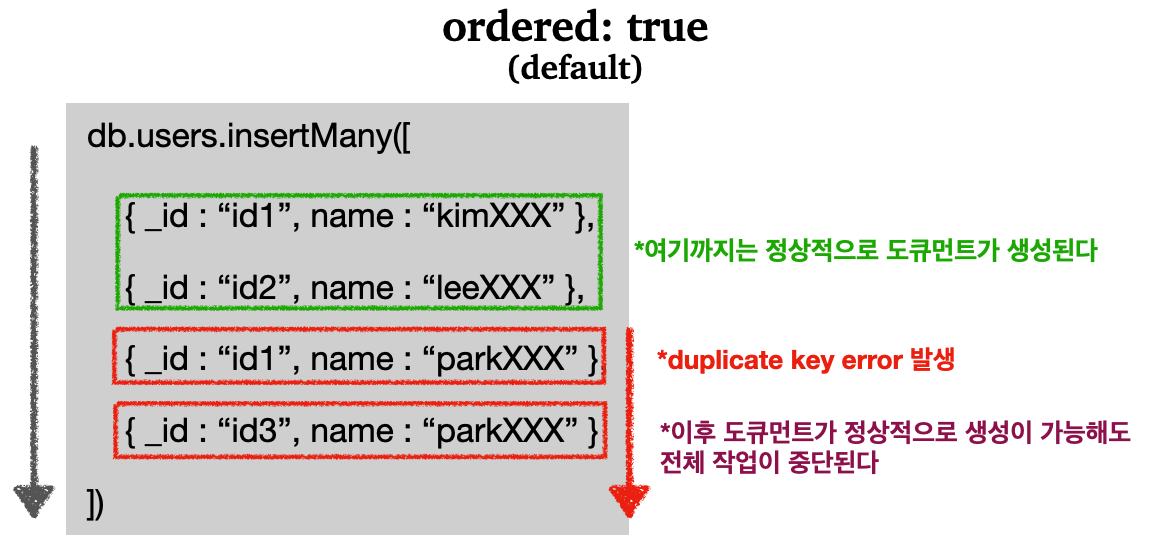
- 이후에
_id: "id3"로 된 도큐먼트를 정상적으로 생성이 가능해도, 기본적으로 옵션이ordered: true로 설정이 되어있기 때문에 도큐먼트 생성이 실패한 곳 부터 전체 작업이 중단된다 - 여기서 알아야 할 것은, 실패 전까지의 반영된 작업은 롤백(
rollback)되지 않는다는 것이다- 몽고DB의 트랜잭션에서 다루겠지만, 트랜잭션을 사용하지 않는 이상 롤백되지 않는다
그러면 ordered 옵션을 false로 설정하면 어떻게 될까? 결론적으로 말하자면 작업이 실패한 도큐먼트는 반영되지 않지만, 전체 작업이 중단되지 않고 정상적으로 작업을 반영할 수 있는 도큐먼트는 전부 반영이 된다.
그림으로 살펴보자.
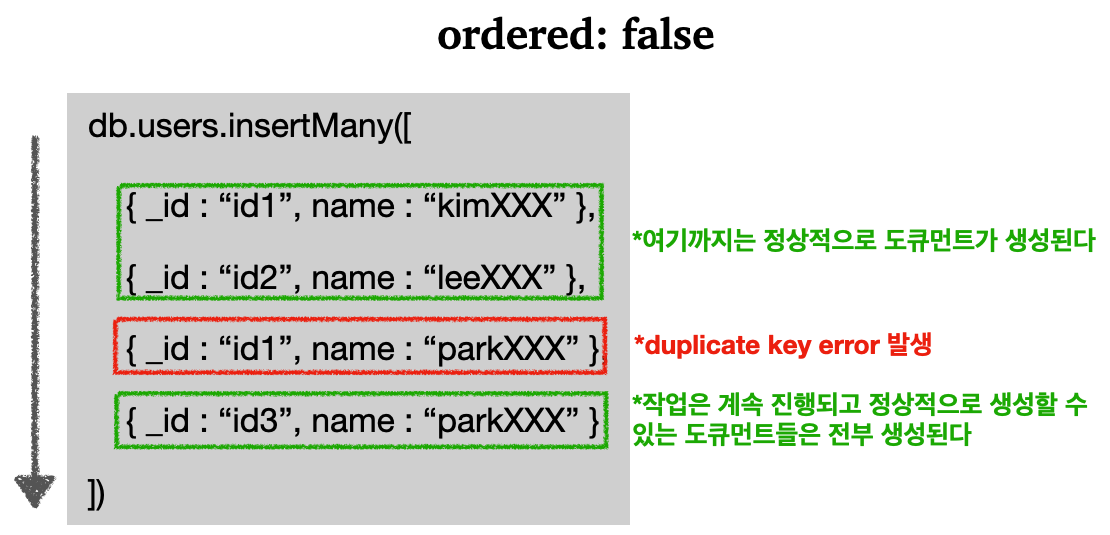
사용법은 다음과 같다.
syntax
4.5 writeConcern 옵션
쓰기 고려(writeConcern) 옵션은 몽고DB가 write 작업에 대한 acknowledgment 수준을 정할 수 있는 옵션이다.
핸드셰이크(Handshake)에서
syn - ack의 그ack이acknowledgment이다.한국어로 번역하면 승인이라는 뜻이다.
writeConcern 옵션을 통해서 몽고DB가 어느 정도 수준(level)의 승인을 성공적인 쓰기 작업으로 인정하는지 정할 수 있다.
(writeConcern 옵션은 로컬 몽고DB에서 사용 불가능하다. 이유는 이 옵션은 여러 노드를 사용하는 레플리케이션 상황에서 사용하기 때문.)
공식문서를 참고하자. https://www.mongodb.com/docs/manual/reference/write-concern/#std-label-write-concern
syntax
insertMany()외에도 모든 쓰기 작업에 대해서 사용 가능-
{w: "majority"}- 대다수의
replica set members로 쓰기 작업이 커밋되었다는 승인을 받으면 성공으로 인정
- 대다수의
-
{w: 1}-
primary node로 부터 승인되면 성공으로 인정 -
standalone(로컬 서버) 상황에서의 기본 옵션
-
-
{w: 0}- 쓰기 작업을 바로 서버로 보내고 성공으로 인정
- 승인을 기다리지 않는다
- 가장 빠르지만, 성공에 대한 보장 확률은 제일 낮다
-
{w: <number>}- 몇 개의
replica set member가 승인을 해야 성공으로 인정하는지 최소 한도를 정할 수 있다 - 예)
{w: 3}는 최소replica set member3개의 승인이 필요
- 몇 개의
-
j옵션과wtimeout옵션도 있다
5. 도큐먼트 수정
5.1 updateOne()
syntax
예시
1
db.users.updateOne({name: "엘링 홀란드"}, {$set: {address: {country: "England", city: "Manchester City"}}})
-
db.collectionName.updateOne(filter, update, option)- 필터로 찾은 첫번째 도큐먼트를 제시한 수정 내용으로 수정한다
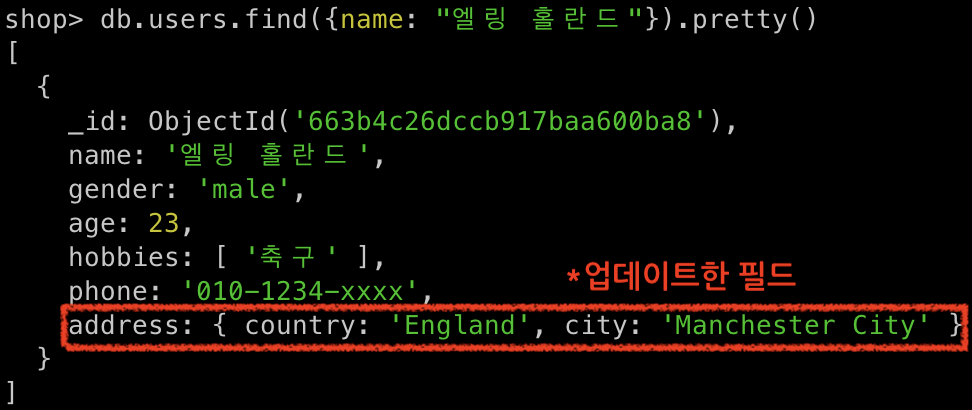
- 예시의 경우
$set을 사용한 것을 볼 수 있다-
$set의 경우 명시한 필드가 존재한다면 해당 필드의 내용을 업데이트 해준다 - 만약 해당 필드가 존재하지 않는다면 필드와 그 내용을 추가한다
-
$set처럼$이 붙은 것들을operator라고 한다
-
아래 표는 도큐먼트의 필드 업데이트를 위한 operator들이다.

https://www.mongodb.com/docs/manual/reference/operator/update/#std-label-update-operators
-
Array에 사용하기 위한operator들도 존재한다
5.2 updateMany()
syntax
예시
1
db.users.updateMany({}, {$inc : {age: 1}})
-
db.collectionName.updateMany(filter, update, option)- 필터로 찾은 모든 도큐먼트들을 제시한 수정 내용으로 수정한다
- 예시의 경우 모든 도큐먼트에 대해서
age필드를1증가시키는 업데이트를 적용한다- 필터에
{}를 사용하면 모든 도큐먼트를 선택한다
- 필터에
update()라는 메서드도 있었지만mongosh가 도입되면서 deprecated 되었다.
6. 도큐먼트 삭제
6.1 deleteOne()
syntax
예시
1
db.users.deleteOne({name: "퓨리 타이슨"})
-
db.collectionName.deleteOne(filter, option)- 필터로 찾은 첫 번째 도큐먼트를 삭제한다
- 예시의 경우
name이퓨리 타이슨으로 찾은 첫 번째 도큐먼트를 삭제한다
6.2 deleteMany()
syntax
예시
1
db.users.deleteMany({"age" : {$gt: 33}})
-
db.collectionName.deleteMany(filter, option)- 필터로 찾은 모든 도큐먼트를 삭제한다
- 예시의 경우
age가33보다 많은 모든 도큐먼트를 삭제한다-
$gt: greater than
-
7. 도큐먼트 조회
7.1 mongoimport
mongoimport를 이용해서 JSON이나 CSV 파일을 몽고DB 데이터베이스로 데이터를 임포트하는 방법을 알아보자. 사용하기 위해서는 mongodb-database-tools을 설치하면 된다.
사용법
1
2
mongoimport --uri mongodb://<username>:<password>@<hostname>:<port>/<DB명> --collection <컬렉션명>
--file <파일디렉토리> --authenticationDatabase admin
-
--drop옵션을 추가하는 경우, 컬렉션이 이미 존재하는 경우 컬렉션을 먼저 삭제해준다
https://github.com/ozlerhakan/mongodb-json-files/blob/master/datasets/books.json의 데이터셋을 이용할 것이다.
1
2
mongoimport --uri mongodb://root:admin@localhost:27017/shop --collection books
--file books.json --authenticationDatabase admin
7.2 find()
syntax
-
db.collectionName.find(query, projection, option)- 뷰(view)나 컬렉션의 더큐먼트들을 쿼리에 맞춰서 조회하고 커서(cursor)를 반환한다
- RDBMS의
ResultSet에 대해 커서를 반환하는 것과 비슷한걸로 생각하면 된다
- RDBMS의
- 뷰(view)나 컬렉션의 더큐먼트들을 쿼리에 맞춰서 조회하고 커서(cursor)를 반환한다
-
반환한 커서를
var키워드를 이용해서 변수에 할당하지 않을 경우 몽고쉘(mongosh)에서 자동으로20번iterate해서, 첫20도큐먼트를 결과로 출력하도록 설정 되어있다- 뒤에서 더 자세히 다룰 예정이다
-
projection을 이용해서 특정 필드만을 조회할 수 있다- 생략시, 기본적으로 모든 필드를 조회한다
find()를 이용해서 다양한 쿼리를 적용해보자.
findOne()
- 찾은 첫 번째 도큐먼트만 조회한다
- 조건에 맞는 첫 번째 도큐먼트만 조회하고 싶을때 사용 가능
pretty()는 사용불가- 커서 반환이 아닌 단일 도큐먼트 반환
7.3 모든 도큐먼트 조회
들어가기에 앞서
7.3~7.7은 커서를 이용하는 것이 아니라, 몽고쉘(mongosh)이 기본적으로20개의 도큐먼트를 출력하는 기능을 이용했다.커서에 대한 내용은 뒤에서 더 자세히 다룰 예정이다.
syntax
db.collection.find({})
{}를 생략가능
예시
1
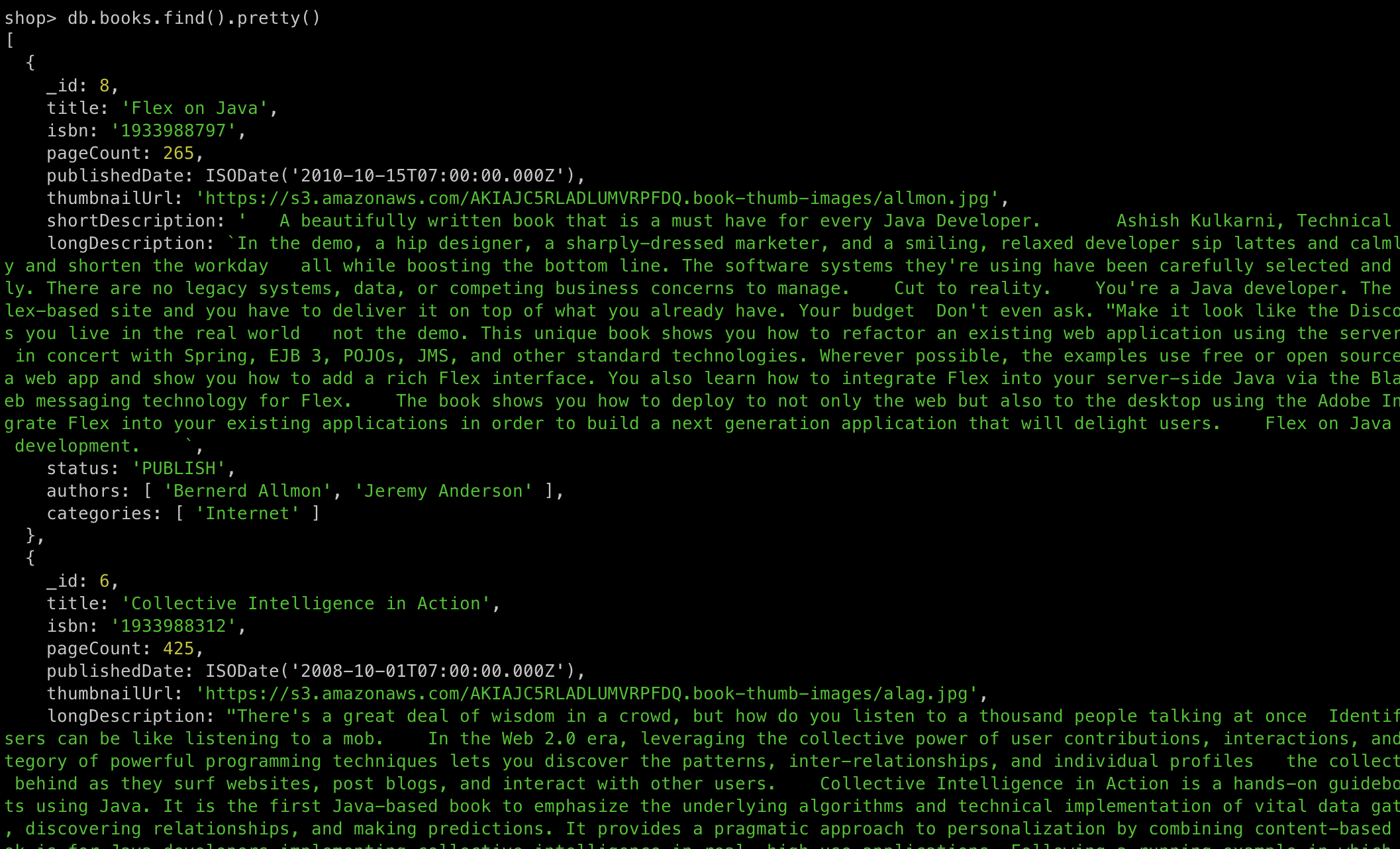
db.books.find().pretty()
예시의 경우
find()에 빈 쿼리를 사용했다. 이 경우 컬렉션의 모든 도큐먼트를 조회한다SQL은SELECT * FROM books;에 해당pretty()를 사용하면 결과를 더 정리된 포맷으로 확인 가능
7.4 동등 조건으로 도큐먼트 조회
syntax
db.collection.find({<field>:<value>})
예시
1
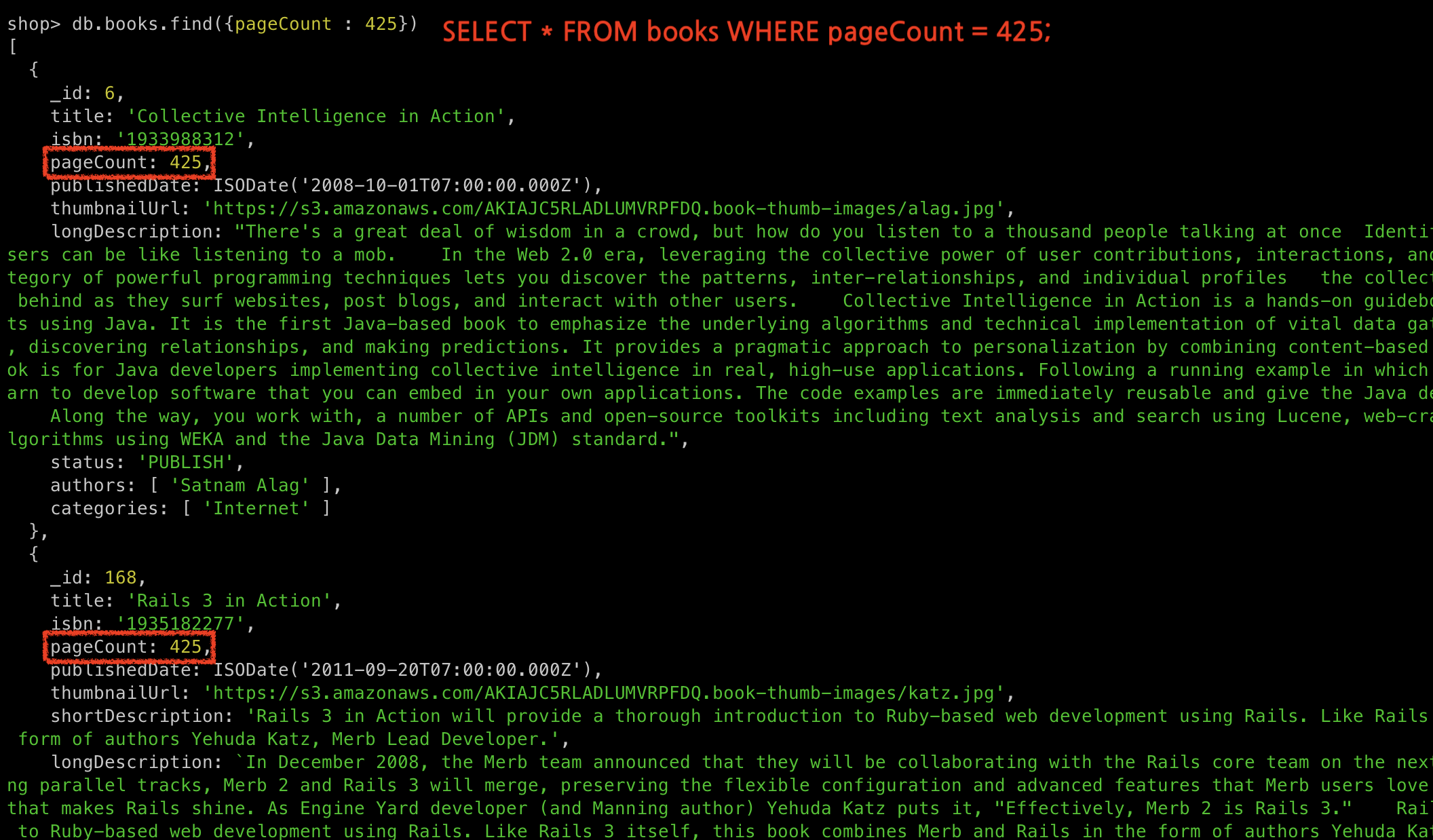
db.books.find({pageCount : 425})
-
db.collection.find({<field>:<value>})-
field의<value>값과 동일한 도큐먼트들을 조회한다
-
예시의 경우
pageCount가425인 모든 도큐먼트들을 조회한다-
SQL은SELECT * FROM books WHERE pageCount = 425;에 해당
7.5 쿼리 오퍼레이터를 이용한 조건으로 도큐먼트 조회, Projection
syntax
db.collection.find({ <field1>: { <operator1>: <value1> }, ... })
예시
1
2
3
4
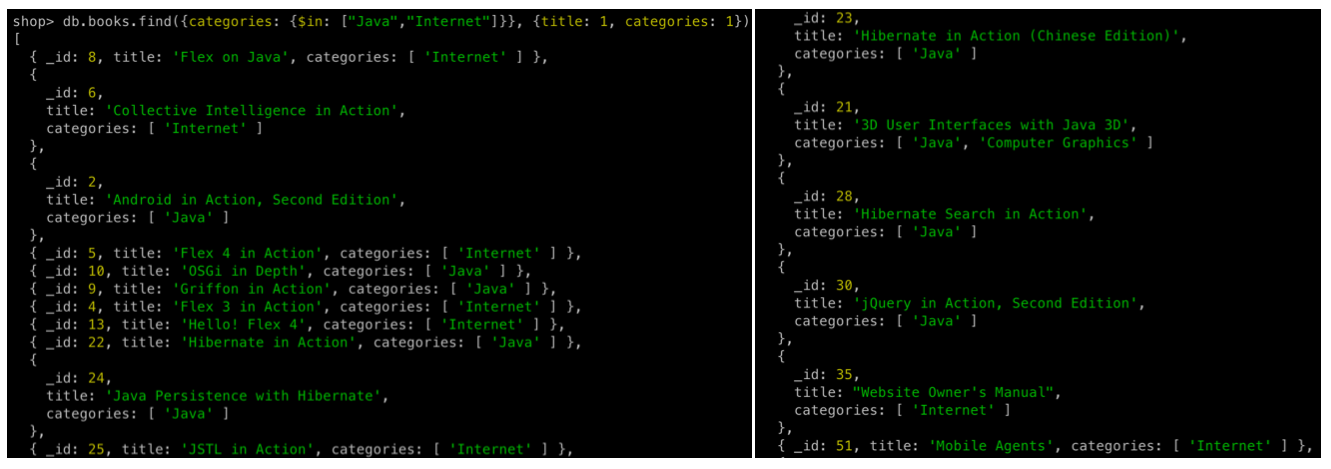
db.books.find(
{categories: {$in: ["Java","Internet"]}},
{title: 1, categories: 1}
)
-
{categories: {$in: ["Java","Internet"]}}-
categories안에Java또는Internet이 하나라도 포함되어 있으면 조회 -
SQL은SELECT * FROM books WHERE categories in ("Java", "Internet")에 해당한다
-
-
{title: 1, categories: 1}- 프로젝션(Projection)
-
title과categories필드만 조회한다 -
_id의 경우1로 설정하지 않아도 무조건 조회한다. 조회하고 싶지 않다면 명시적으로_id: 0으로 설정해야 한다 -
SQL은SELECT _id, title, categories FROM에 해당한다
7.6 AND, OR 조건
AND 예시
1
2
3
4
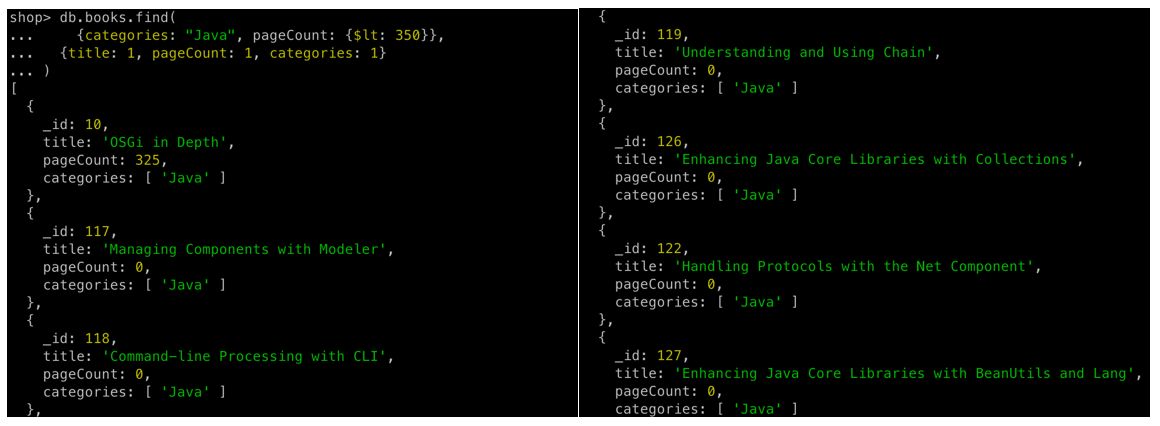
db.books.find(
{categories: "Java", pageCount: {$lt: 350}},
{title: 1, pageCount: 1, categories: 1}
)
-
{categories: "Java", pageCount: {$lt: 350}}- 기본적으로
{}안에 아무것도 명시하지 않을 경우,로AND연산으로 처리한다
- 기본적으로
-
SQL은SELECT _id, title, pageCount, categories FROM books WHERE catgories = "Java" AND pageCount < 350;에 해당한다
OR 예시
1
2
3
4
5
6
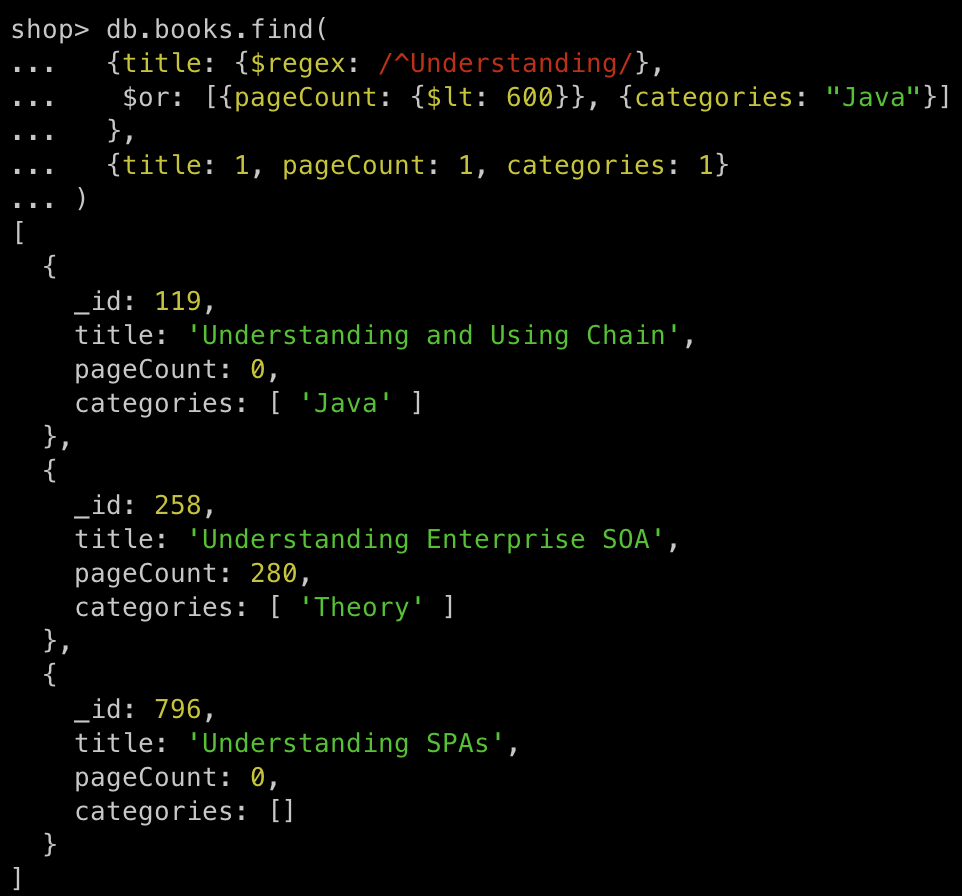
db.books.find(
{title: {$regex: /^Understanding/},
$or: [{pageCount: {$lt: 600}}, {categories: "Java"}]
},
{title: 1, pageCount: 1, categories: 1}
)
-
title: {$regex: /^Understanding/}- 정규표현식을 이용해서
title이Understanding으로 시작하는 도큐먼트 조회
- 정규표현식을 이용해서
-
$or: [{pageCount: {$lt: 600}}, {categories: "Java"}]-
{pageCount: {$lt: 600}}와{categories: "Java"}는OR연산으로 연결 -
pageCount가600미만이거나categories가Java인 도큐먼트 조회
-
title: {$regex: /^Understanding/}와$or: [{pageCount: {$lt: 600}}, {categories: "Java"}]는AND연산으로 연결-
SQL은SELECT _id, title, pageCount, categories FROM books WHERE title LIKE "Understanding%" AND (pageCount < 600 OR categories = "Java");에 해당한다
7.7 Nested 도큐먼트의 필드를 이용해서 조회
예시
1
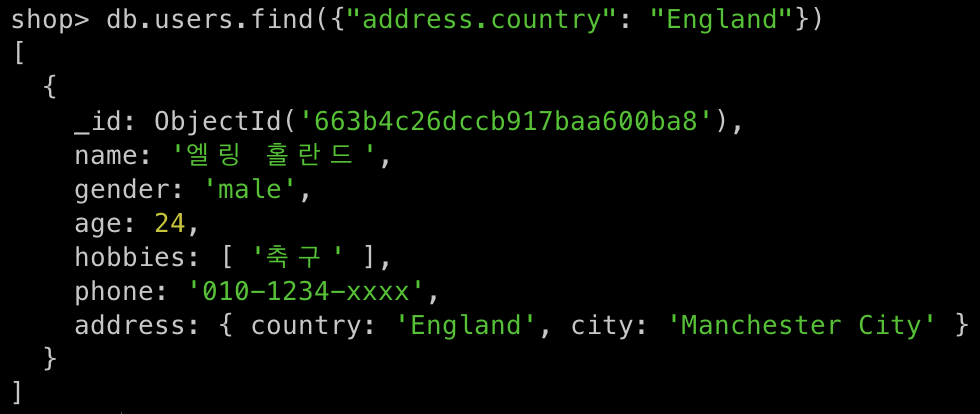
db.users.find({"address.country": "England"})
-
{"<innerDocument>.<field>" : <value>}같은 형태로 사용하면 된다
7.8 find()와 cursor
지금까지 find()를 사용해서 도큐먼트를 조회했지만, find()는 도큐먼트를 반환하는 메서드가 아니다! 이전에도 설명했지만, find()는 커서(cursor)를 반환한다. mongosh(몽고쉘)에서는 반환한 커서를 var 키워드를 이용해서 변수에 할당하지 않을 경우 몽고쉘(mongosh)에서 자동으로 20번 iterate 해서, 첫 20 도큐먼트를 결과로 출력하도록 설정 되어있다.
그러면 커서를 매뉴얼하게 iterate하는 방법에 대해서 알아보자.
몽고쉘에서는 find()를 통해 반환 받은 커서를 var 키워드를 이용해서 변수에 할당하면 커서는 자동으로 20번 iterate 하지 않는다
이때 커서를 할당한 변수를 호출하면 기존에 몽고쉘이 해줬던 것 처럼 20번 iterate 해서 매칭 도큐먼트들을 출력할 수 있다.
예시
1
2
3
var booksCursor = db.books.find({}, {title: 1, categories: 1});
booksCursor.pretty()
- 기존에
find().pretty()는 결국에 커서에pretty()메서드를 사용했던 것이다 - 커서를 할당받은 변수에
pretty()를 사용할 수 있다는 뜻이다
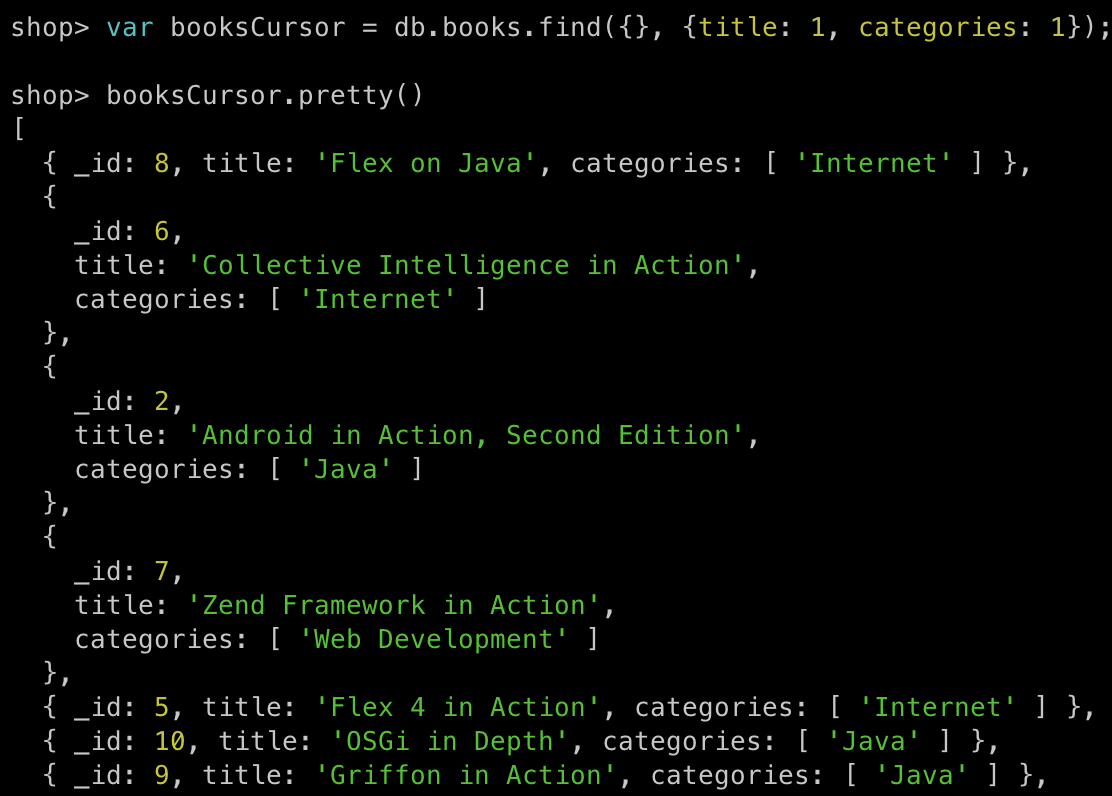
그러면 이번에는 next() 메서드를 이용해서 매칭된 도큐먼트에 접근해보자.
예시
1
2
3
4
5
var booksCursor = db.books.find({categories: "Java"}, {title: 1, categories: 1});
while (booksCursor.hasNext()) {
printjson(booksCursor.next());
}
-
hasNext(): 현재 커서가 더iterate이 가능하다면(도큐먼트가 더 남았다면)true를 반환한다 -
next(): 현재 커서 위치 기준으로 다음 도큐먼트를 가져온다- 다음 도큐먼트를 가져온후 커서 위치를 다음으로 옮긴다
- 위 예시는 반복문을 돌면서 필터에 매칭된 모든 도큐먼트를 출력한다
- 커서의 현재 위치 기준, 다음 도큐먼트가 존재하지 않으면
hasNext()는false를 리턴하고 반복문이 끝난다
- 커서의 현재 위치 기준, 다음 도큐먼트가 존재하지 않으면
이번에 forEach()를 사용해보자.
forEach() syntax
function: 자바스크립트 코드가 들어갈 수 있다
예시
1
2
3
var booksCursor = db.books.find({categories: "Java"}, {title: 1, categories: 1});
booksCursor.forEach(printJson)
- 바로 이전
next()를 이용한 예시와 똑같은 결과를 얻을 수 있다
7.9 sort()
result set의 정렬 기준을 정할 수 있다.
대표적으로 오름차순/내림차순 정렬을 정할 수 있다.
공식 문서 참고 : https://www.mongodb.com/docs/manual/reference/method/cursor.sort/#syntax
예시
1
db.books.find({}, {title: 1, pageCount: 1, categories: 1}).sort({pageCount: 1}).pretty()
-
pageCount를 기준으로 결과를 오름차순 정렬을 한다-
-1로 설정시 내림차순 정렬을 한다
-
- 여러 필드를 기준으로 정할 수 있다
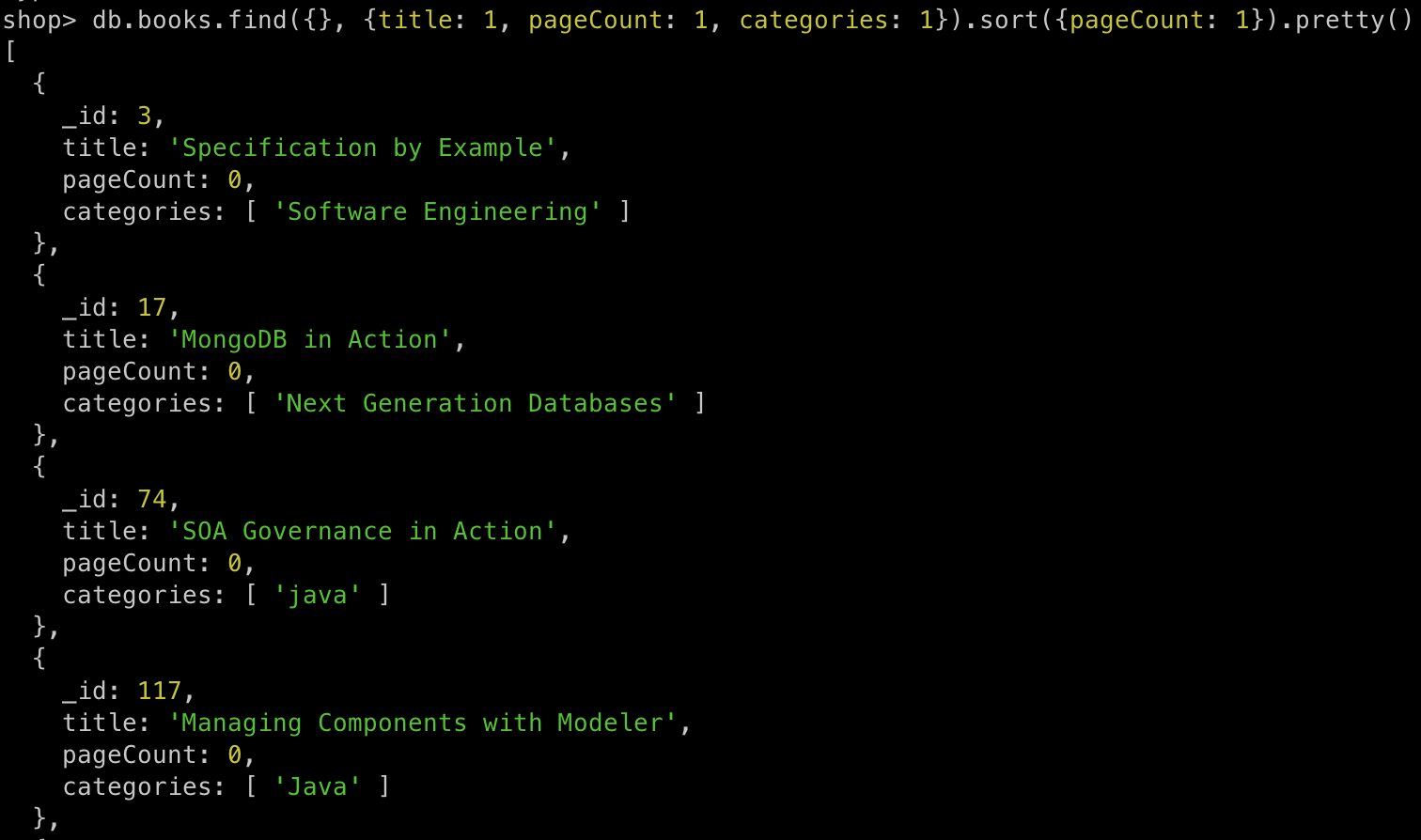
pageCount를 기준으로 오름차순 정렬
Reference
- https://www.mongodb.com/docs/manual/crud/
- https://www.mongodb.com/docs/mongodb-shell/run-commands/
- https://www.mongodb.com/docs/manual/reference/write-concern/#std-label-write-concern
- https://www.mongodb.com/docs/manual/reference/operator/update/#std-label-update-operators
- 사용 데이터셋 : https://github.com/ozlerhakan/mongodb-json-files/blob/master/datasets/books.json
- https://www.mongodb.com/docs/manual/reference/method/cursor.sort/#syntax
Comments powered by Disqus.